Linéarisation autour d’un état d’équilibre f(t,x,v)=feq(v)+εg(t,x,v) et E(t,x)=εe(t,x):
{∂tg+v∂xg+edvfeq=0∂xe=∫Rgdv
Fourier-Laplace (condition initiale nulle) :
∂t⋅→−iω⋅∂x⋅→ik⋅
d’où
{ik(v−kω)g=−edvfeqike=∫gdv
La première équation nous donne :
g=k(v−kω)iedvfeq
La seconde donne alors :
e=−ki∫k(v−kω)iedvfeqdv
soit :
e(1−k21∫v−kωdvfeqdv)=0
On note alors :
D(ω,k)=1−k21∫Rv−kωdvfeqdv
Calcul de l’intégrale pour une maxwellienne :
Étude de l’intégrale dans le cas feq(v)=Mρ,u,T(v)=2πTρe−2T∣v−u∣2 :
∫Rv−βdvMρ,u,T(v)dv=∫v−β−T(v−u)Mρ,u,T(v)dv=−T1∫v−β(v−β+β−u)Mρ,u,T(v)dv=−Tρ−Tβ−u∫v−βMρ,u,T(v)dv
Étudions plus particulièrement l’intégrale : ∫v−βMρ,u,T(v)dv :
∫v−βMρ,u,T(v)dv=2πTρ∫v−βe−2T∣v−u∣2dv=2πTρ∫v−u+u−βe−(2Tv−u)2dv
on effectue le changement de variable z=2Tv−u, dz=2Tdv :
∫v−βMρ,u,T(v)dv=2πTρ∫2Tz+u−βe−z22Tdz=2πTρ∫z+2Tu−βe−z2dz
On pose Z:ξ↦π1∫z−ξe−z2dz :
∫v−βMρ,u,T(v)dv=2TρZ(2Tβ−u)
D’où :
∫v−βdvMρ,u,T(v)dv=−Tρ−T2Tρ(β−u)Z(2Tβ−u)
soit :
∫Rv−βdvMρ,u,T(v)dv=−Tρ(1+2Tβ−uZ(2Tβ−u))
Calcul de l’intégrale pour une distribution de Dirac
Étude de l’intégrale dans le cas feq(v)=δu(v) :
∫Rv−βdvδu(v)dv=−∫δu(v)(v−β1)′dv=−∫δu(v)(v−β)21dv
soit :
∫Rv−βdvδu(v)dv=−(u−β)21
Test numérique
On étudie le cas d’un triple bump :
feq=M1−α,0,Tc+Mα/2,u,1+Mα/2,−u,1
la relation de dispersion s’écrit alors :
D(ω,k)=1−k21[−Tc1−α(1+k2TcωZ(k2Tcω))−2α(1+2kω−uZ(2kω−u))−2α(1+2kω+uZ(2kω+u))]
On souhaite comparer ce test à celui de la modélisation hybride avec une distribution de Dirac pour représenter les particules froides :
feq=(1−α)δ0+Mα/2,u,1+Mα/2,−u,1
Ce qui correspond à Tc→0. La relation de dispersion s’écrit alors :
D(ω,k)=1−k21[−(1−α)(ωk)2−2α(1+2kω−uZ(2kω−u))−2α(1+2kω+uZ(2kω+u))]
Ce qui revient à dire que :
1+zZ(z)≈z→+∞z22
avec z∈C n’évoluant que selon un axe parallèle à la droite des réelles, c’est-à-dire que seulement sa partie réelle tend vers l’infini.
2019-10-25
Lawson pour VPHL
On s’intéresse au problème de Vlasov-Poisson hybride linéarisé (VPHL) :
⎩⎪⎪⎨⎪⎪⎧∂tuc=E∂tE=−ρcuc−∫vfhdv∂tf^h=−ikvf^h−E∂vfh
par commodité, nous noterons fh=f^h. Ce problème se réécrit :
∂tU⎝⎛ucEfh⎠⎞=A⎝⎛0−ρc010000−ikv⎠⎞⎝⎛ucEfh⎠⎞+N(U)⎝⎛0−∫vfhdv−E∂vfh⎠⎞∂tU=AU+N(U)
Pour introduire une méthode de Lawson, on utilise le changement de variable suivant V=e−tAU, l’exponentielle de la matrice A peut se calculer et vaut :
e−tA=⎝⎜⎜⎛cos(ρct)ρcsin(ρct)0−ρcsin(ρct)cos(ρct)000eikvt⎠⎟⎟⎞
On calcule maintenant la valeur de ∂tV :
∂tV=−Ae−tAU+e−tA∂tU
soit :
∂tV=−Ae−tAU+e−tAAU+e−tAN(U)
En écrivant etA sous forme de série :
etA=k∈N∑k!tkAk
il devient évident que AetA=etAA, i.e. que A et etA commutent.
d’où :
∂tV=e−tAN(U)=e−tAN(etAV)=N~(t,V)
On obtient une forme propice à l’utilisation d’une méthode RK(s,n), ce qui permettra d’exprimer le schéma de Lawson associé. Pour l’exemple, nous utiliserons la méthode RK(3,3) dit de Shu-Osher. Les méthodes dites de Shu-Osher sont des méthodes de type Runge-Kutta réécrite pour réutiliser les résultats précédents de n’effectuer qu’un seul appel à la fonction non linéaire par étage, ces méthodes sont intéressantes lorsque le coût de calcul est plus long que le temps d’accès à la mémoire (et que cette dernière n’est pas limitée). Dans ce cas, ce qui nous intéresse est l’obtention de la fonction de stabilité, et celle-ci est plus simple à obtenir à la main dans le cas d’une méthode dite de Shu-Osher. Pour les notations, nous écrivons cette méthode pour résoudre un problème du type u˙=L(t,u) :
u(1)u(2)un+1=un+ΔtL(tn,un)=43un+41u(1)+41ΔtL(tn+Δt,u(1))=31un+32u(2)+32ΔtL(tn+2Δt,u(2))
Nous écrivons maintenant cette méthode pour le problème ∂tV=e−tAN(etAV) :
V(1)V(2)Vn+1=Vn+Δte−tnAN(etnAVn)=43Vn+41V(1)+41Δte−(tn+Δt)AN(e(tn+Δt)AV(1))=31Vn+32V(2)+32Δte−(tn+2Δt)AN(e(tn+2Δt)AV(2))
Dans un premier temps nous approximons la non linéarité N(U) par :
N(U)≈⎝⎛00000000λ⎠⎞=ΛΛ commute avec etA, donc la méthode RK(3,3) dit de Shu-Osher se réécrit :
V(1)V(2)Vn+1=Vn+ΔtΛVn=(I+ΔtΛ)Vn=43Vn+41V(1)+41ΔtΛV(1)=(43I+41(I+ΔtΛ)2)Vn=31Vn+32V(2)+32ΔtΛV(2)=pRK(3,3)(ΔtΛ)Vn
avec pRK(3,3) le polynôme défini par :
pRK(3,3)(z)=1+z+2z2+6z3
On cherche maintenant à exprimer ceci en fonction de notre inconnue U :
e(tn+Δt)AUn+1=pRK(3,3)(ΔtΛ)etnAUn
soit :
Un+1=e−(tn+Δt)ApRK(3,3)(ΔtΛ)etnAUn
Maintenant il reste à savoir si etA et pRK(3,3)(ΔtΛ) commutent, on sait déjà que I et etA commutent, Λ et etA aussi, calculons Λ2 :
Λ2=⎝⎛00000000λ2⎠⎞
donc Λ2 et etA commutent, d’où :
Un+1=pRK(3,3)(ΔtΛ)eΔtAUn
On peut calculer la norme de etA avec notre matrice A et on obtient ∣∣∣∣∣∣etA∣∣∣∣∣∣2=1, ∀t. Comme pour le cas cinétique K, l’étude de stabilité de la méthode de Lawson revient à l’étude de la stabilité de la méthode RK(s,n) sous-jacente. Le calcul a été effectué pour une méthode RK(3,3), mais se généralise facilement puisque Λ commute avec etA, ∀t∈R. De façon plus générale nous obtenons donc le résultat :
pLRK(s,n)(z)=pRK(s,n)(z)eΔtA
où pLRK(s,n) est la fonction de stabilité de la méthode de Lawson associée à la méthode Runge-Kutta RK(s,n) de fonction de stabilité pRK(s,n).
Intéressons nous maintenant à la linéarisation de N(U) suivante :
N(U)≈⎝⎛0000000νλ⎠⎞=Λ˙
On remarque alors que Λ˙ et etA ne commutent pas, on a pas l’égalité de fonction de stabilité :
pLRK(s,n)(ΔtΛ˙)=pRK(s,n)(ΔtΛ˙)eΔtA
La linéarisation permettant d’obtenir le même résultat que dans le cas scalaire peut s’interpréter d’un point de vue physique comme :
Jc≫Jhi.e. le courant des particules chaudes est négligeable devant celui des particules froides ; ou, comme le cas scalaire, cela revient à ne considérer que le transport 2D pour étudier la stabilité des méthodes numériques sur l’équation de Vlasov.
On considère donc que la seule source de CFL est le transport en v des particules chaudes fh.
Dépôt sur HAL
J’ai effectué le dépôt sur HAL de l’article avec Lukas et Nicolas Exponential methods for solving hyperbolic problems with application to kinetic equations. J’ai enfin compris ce qui bloquait dans le dépôt simultané sur arXiv, toutes les images doivent être au format jpeg, png ou pdf ; une image était au format eps (autorisé uniquement pour TeX ou LaTeX et non pdfLaTeX…) J’ai effectué les modifications requises et j’attends la validation du dépôt par HAL. Nicolas évoquait de le soumettre à JCP.
L’équation de Poisson : ikE^(t,k)=∫f^hdv, est-elle vérifiée ?
∂t⎝⎛ucEf^h⎠⎞+⎝⎛0ρc0−10000ikv⎠⎞⎝⎛ucEf^h⎠⎞+⎝⎛0∫fhdvE∂vfh⎠⎞=0
de la forme :
∂tU+AU+N(U)=0
une forme propice à l’utilisation des méthodes de Lawson.
φΔt[a](U(2))=⎝⎛f^hn+1ucn+1E^n+1⎠⎞=⎝⎜⎜⎛e−ikvΔtf^h(2)uc(2)E^(2)−ki∫f^hn+1dv+ki∫f^h(2)dv⎠⎟⎟⎞=Un+1
La formulation de la dernière équation d’Ampère, le calcul de E^n+1, permet de vérifier simultanément l’équation de Poisson.
2019-11-04
Le schéma de Lawson pour la résolution de VPHL n’a pas lieu de changer. Le schéma numérique fait intervenir des exponentielles qui ne dépendent que du pas de temps. Dans le cas scalaire, il était simple de recalculer ces valeurs, dans le cas matriciel il est intéressant d’assembler les matrices en amont. Le calcul du schéma fait intervenir la matrice eciΔtA :
eciΔtA=⎝⎛cos(ciΔt)sin(ciΔt)0−sin(ciΔt)cos(ciΔt)000eiciΔtkv⎠⎞
sympy ne simplifie pas comme il faut les termes lorsque ci est un réel quelconque, mais pas de problème lorsque ci>0 ou ci<0, de même que le cas ci=0 qui ne se rencontre jamais. Si ci est quelconque il travaille sur ∣ci∣ et fait intervenir des ci∣ci∣ pour jouer sur la parité des fonctions sinus et cosinus.
Une fonction calculant l’exponentielle eciΔtA est intéressant (plutôt qu’espérer que ublas de boost me calcule à chaque itération l’exponentielle), il n’est pas envisageable d’avoir un assemblage définitif de la matrice en début de simulation car :
eiciΔtkv peut prendre beaucoup de valeurs, mais ce n’est qu’un terme diagonal à modifier.
On souhaite faire évoluer nos simulations vers des méthodes à pas de temps adaptatif, donc Δt n’est pas constant, donc le bloc diagonal ne peut pas s’assembler définitivement en début de simulation.
La matrice ne peut être assemblée définitivement, mais on peut conserver la même zone mémoire tout au long de la simulation. La librairie ublas de boost:: en particulier d’effectue pas d’affectation par défaut des valeurs lors de l’allocation de la matrice ; conserver la même zone mémoire permet de ne pas affecter 4 zéros à chaque fois que cette matrice est nécessaire.
Dans la pratique il est même inutile d’effectuer l’assemblage de la matrice, il sera bien plus performant d’effectue directement l’assemblage du produit matrice-vecteur dans une fonction.
2019-11-06
J’ai implémenté le WENO-SL (semi-Lagrangien) dans un code de test 1Dx, de transport à vitesse à vitesse constante, etc. Le WENO-SL est décrit dans Qiu:2011 ou Qiu:2010.
Simulation de :
ut+ux=0
avec Tf=0.25, Δx=1001, x∈[0,1] (périodique), RK(4,4) comme intégrateur en temps et 5 condtions initiales différentes : une période de c
Comparaison des différentes méthodes WENO
On remarque que le schéma WENO3 diffuse un peu plus que les autres WENO d’ordre 5 : WENO5 (qui est le WENO standard WENO-JS), WENO-M et WENO-Z, on remarque que le WENO-B de Banks oscille (constatation déjà faite). Le WENO-SL diffuse encore plus que les autres. Je trouve ce résultat relativement étrange, je n’épargne donc pas une erreur dans mon implémentation.
La présentation du WENO-SL est faite avec comme intégrateur en temps du Euler explicite. Puisqu’il est nécessaire de faire entrer du Δt dans la méthode WENO-SL, je ne sais pas si cela se mêle correctement avec un autre intégrateur en temps (comme RK(4,4) utilisé dans cette simulation).
Correction/compréhension de WENO-SL
En réalité, dans la construction de la méthode WENO-SL, la discrétisation s’effectue simultanément en temps et en espace, il n’y a pas d’intégrateur en temps à proprement parlé, dans mon code de simulation de test 1D cela revient à utiliser une méthode d’Euler explicite et de diviser l’approximation ux par Δt. On obtient alors des résultats plus cohérent (correction effectuer jeudi à 14h).
Comparaison des différentes méthodes WENO
On remarque alors que le WENO-SL donne un très bon résultat sur une discontinuité, bien meilleur que WENO-Z (qui est une optimisation du WENO5 classique WENO-JS pour minimiser la diminution d’ordre lors d’une discontinuité). Ce résultat est trompeur car le transport s’effectue à vitesse 1, donc une méthode semi-lagrangienne est considérée comme exacte.
Je n’ai pas effectué de mesure d’ordre sur ce schéma (ordre en espace et en temps du coup ?).
Résolution de :
ut+32ux=0
Avec les mêmes paramètres numériques.
Comparaison des différentes méthodes WENO
Dans ces conditions, WENO-SL fait aussi bien que WENO-Z. Un test similaire a été effectué avec une vitesse négative −32, et on retrouve bien les mêmes résultats. Cela permet de vérifier l’implémentation des flux, puisque dépendant du signe de la vitesse.
2019-11-08
Compte-rendu avec Nicolas
J’ai commencé à étudier l’ordre en temps (normalement exact) et en espace (normalement d’ordre 5) du WENO-SL, mais mon résultat préliminaire me donnait un schéma d’ordre 1 en temps et d’ordre 5 en espace (avec une erreur qui sature très vite à log(Δt). Mon erreur dans le code provient (vraisemblablement) du fait que je choisis des Δt qui dépendent de Δx, ce qui implique un nombre d’itération ΔtTf non entier. Je dois donc faire en sorte, pour les 2 mesures d’ordre, d’avoir ΔtTf∈N.
On a également discuté du schéma de Lawson pour VPHL. J’avais laissé tombé les calculs pour la non-linéarité Λ˙ avec un terme extra-diagonal, car je ne trouvais pas de forme simple car les matrices ne commutent pas. En détaillant chaque terme des matrices avec Nicolas, il semblerait possible d’avoir une forme exploitable pour l’étude généralisée des ordres supérieur à 1.
On a longuement discuté de WENO-SL et de son interprétation comme une interpolation semi-lagrangienne. La version de WENO-SL par Qiu continue de faire apparaître des flux et non une interpolation. La version semi-lagrangienne par Francis Filbet semble plus sympathique, mais utilise des polynômes de Hermite, et donc à un moment une approximation de la dérivée de u. Je dois me replonger un peu plus dans les papiers de Shu sur la construction de WENO, pour être certain de la construction des flux et l’interprétation que Nicolas veut en faire comme une interpolation (pour retrouver une méthode semi-lagrangienne).
TODO:
corriger le script pour obtenir l’ordre en t et x
calculer les valeurs propres de etA pour être certain du résultat donné par sympy : ∣∣∣∣∣∣etA∣∣∣∣∣∣2=1
comparer les polynômes d’interpolation de WENO (et comprendre comment on les calcule), et comparer la version linéarisé avec le polynôme d’interpolation du semi-lagrangien. Voir papier de Francis sur du HWENO (pour WENO semi-lagrangien avec polynôme de Hermite).
Avancement sur les petits trucs à vérifier
L’erreur est bien constante avec Δt, et on atteint l’erreur numérique. En x on retrouve bien la pente de 5, et n’est pas saturé par Δt.
Les valeurs propres de e−tA sont e−itkv et cos(t)±isin(t). Ceci nous donne bien des valeurs propres de module 1.
Ordre de WENO-SL en Δt, le schéma est exacte en tempsOrdre de WENO-SL en Δx, le schéma est d’ordre 5 en espace
2019-11-15
Cette semaine j’ai surtout effectué de l’enseignement et de la correction de copies. J’ai aussi été confronté à sympy et la difficulté de lui faire effectuer des simplifications qui me semblaient évidentes. J’ai réussi à obtenir le polynôme de stabilité d’une méthode de Lawson basée sur RK(3,3) pour le problème suivant :
∂tU+AU+N(U)
en linéarisant N(U) avec une matrice Λ˙ définie par :
Λ˙=⎝⎛0000000μλ⎠⎞
On obtient alors de manière un peu brute avec sympy :
Un+1=⎣⎢⎢⎢⎢⎢⎡100010−6Δtμ(Δt2λ2eiΔtkvsin(2Δt+tn)+Δtλe2iΔtkvsin(Δt+tn)+2ΔtλeiΔtkvsin(2Δt+tn)+e23iΔtkvsin(tn)+e2iΔtkvsin(Δt+tn)+4eiΔtkvsin(2Δt+tn))e−ikv(23Δt+tn)6Δtμ(Δt2λ2eiΔtkvcos(2Δt+tn)+Δtλe2iΔtkvcos(Δt+tn)+2ΔtλeiΔtkvcos(2Δt+tn)+e23iΔtkvcos(tn)+e2iΔtkvcos(Δt+tn)+4eiΔtkvcos(2Δt+tn))e−ikv(23Δt+tn)6Δt3λ3+2Δt2λ2+Δtλ+1⎦⎥⎥⎥⎥⎥⎤Un
Cette matrice est le fruit du polynôme en ΔtΛ˙ :
6Δt3e−2ΔtA−tnAΛ˙e−2ΔtAΛ˙eΔtAΛ˙etnA+6Δt2e−ΔtA−tnAΛ˙eΔtAΛ˙etnA+6Δt2e−2ΔtA−tnAΛ˙e−2ΔtAΛ˙eΔtA+tnA+6Δt2e−2ΔtA−tnAΛ˙e2ΔtAΛ˙etnA+6Δte−tnAΛ˙etnA+6Δte−ΔtA−tnAΛ˙eΔtA+tnA+32Δte−2ΔtA−tnAΛ˙e2ΔtA+tnA+1
Ce qui est important c’est que uniquement la dernière colonne est remplie. On a à chaque fois quelque chose de homogène à une puissance de Δtλ : Δt3λ2μ, Δt2λμ, Δtμ. Et pour μ=0 on retrouve bien la même matrice que dans le cas déjà traité précédemment.
J’ai passé du temps avec sympy pour conserver des cosinus et sinus dans la forme finale (ceux-ci étaient écrits en complexe sous leur forme polaire), et ainsi qu’écrire ceci de manière à pouvoir tester le plus simplement possible avec d’autres schémas. Puisque je ne sais pas trop quoi conclure avec cette matrice, je n’ai pas cherché encore à effectuer ce travail sur d’autres schémas.
Pour information, pour obtenir ce résultat, j’ai défini une fonction permettant de calcul etA, et je connais les instants t où cette fonction sera évaluée dans le schéma (en prennant les notations d’un tableau de Butcher, c’est en e±(tn+ciΔt)A. Puis je demande à sympy de me substituer toutes ces exponentielles de matrices et Λ˙ simultanément pour obtenir ce résultat.
def m_exp(x): t = (x/A).simplify() M = sp.Matrix([[sp.cos(t),sp.sin(t),0],[-sp.sin(t),sp.cos(t),0],[0,0,sp.exp(-sp.I*k*v*t)]])return Mlist_t =sum([[t,-t] for t in [tn,tn+dt,tn+dt/2,dt,dt/2]],[])list_subs = [(sp.exp(t*A).expand(),m_exp(t*A)) for t in list_t]+[(L,mL)]p.subs(list_subs,simultaneous=True) # p est notre polynôme en $\Delta t\dot{\Lambda}$
J’ai pu testé avec un autre schéma RK(3,3) que le schéma RK(3,3) de Shu-Osher, défini par :
u(1)u(2)un+1=un+21ΔtL(tn,un)=3un−2u(1)+2ΔtL(tn+21Δt,u(1))=−31un+u(1)+31u(2)+61ΔtL(tn+Δt,u(2))
Et la fonction de stabilité du schéma de Lawson induit, avec une non-linéarité Λ˙ (qui ne commute pas avec etA) est différente, et donc la matrice de stabilité varie aussi.
2019-11-20
Prenons le schéma de Lawson induit par le schéma RK(3,3) de Shu-Osher, pour la résolution de l’équation :
∂tU=AU+N(U)
avec U=(uvEf^h)T, et :
A=⎝⎛0−ρc010000−ikv⎠⎞N(U)=⎝⎛0−∫vfhdv−E∂vfh⎠⎞
Avec ces notations, le schéma s’écrit :
U(1)U(2)Un+1=eΔtAUn+ΔteΔtAN(Un)=43e2ΔtAUn+41e−2ΔtAU(1)+41Δte−2ΔtAN(U(1))=31eΔtLUn+32e2ΔtAU(2)+32Δte2ΔtAN(U(2))
Détaillons maintenant le premier étage :
⎝⎜⎜⎛uc(1)E(1)f^h(1)⎠⎟⎟⎞=⎝⎜⎜⎛cos(ρcΔt)−ρcsin(ρcΔt)0ρcsin(ρcΔt)cos(ρcΔt)000e−ikvΔt⎠⎟⎟⎞⎝⎛ucnEnf^hn⎠⎞+Δt⎝⎜⎜⎛cos(ρcΔt)−ρcsin(ρcΔt)0ρcsin(ρcΔt)cos(ρcΔt)000e−ikvΔt⎠⎟⎟⎞⎝⎛0−∫vfhndv−En∂vfhn⎠⎞
avec (ucni)i, (Ein)i, et (f^hnι,k)ι,k avec i indice d’espace xi=iΔx, k indice de vitesse vk=kΔv et ι indice de phase κι=L2πι. Pour la transformée de Fourier nous utilisons une FFT (Fast Fourier Transform), et l’algorithme impose un même nombre de cellules en espace que de nombres d’onde, il est donc possible d’utiliser le même indice pour parcourir l’espace xi=iΔx et la phase κι=L2πι.
Nous obtenons alors par exemple pour le premier étage l’algorithme suivant :
Calcul de (En∂vfhn)j,k avec WENO ou autre, et calcul de (∫vfhndv)j (ceci nécessite d’effectuer une FFT inverse de f^hn, et il s’agit finalement le la seule étape où fh est nécessaire).
Calcul des (uc(1))j et (E(1))j :
ucj(1)Ej(1)=ucjnρccos(ρcΔt)−Ejnρcsin(ρcΔt)+(∫vfhndv)jsin(ρcΔt)=−ucjnρcsin(ρcΔt)+Ejncos(ρcΔt)+(∫vfhndv)jcos(ρcΔt),∀j,xj=jΔx
Boucle pour tout vk : effectuer une FFT pour obtenir (En∂vfhn)ι,k à k fixé, et calcul des (f^h(1))ι,k :
f^hι,k(1)=e−iκιvkΔtf^hι,kn−e−iκιvkΔt(En∂vfhn)ι,k,∀ι,κι=L2πι
L’étape 1 est le calcul de N(Un), puis les étapes 2 et 3 sont indépendantes (donc parallélisables). Les autres étages du schéma de Lawson (quelque soit le schéma RK sous-jacent) suivent la même logique. La boucle sur les κι étant à l’intérieur de la boucle en vk il n’est pas possible d’effectuer le calcul des (uc(1)i,Ei(1)) en même temps que f^h(1)ι,k.
Dans l’algorithme suivant, qui détaille les 3 étages de la méthode, toutes les variables avec des points (X˙) indiquent des variables temporaires ne servant qu’à un étage, ou dans une boucle.
Cette semaine j’ai corrigé le modèle de Vlasov-Poisson Hybride Linéarisé que je considérais comme :
∂tU=AU+N(U)
avec :
U=⎝⎛ucEf^h⎠⎞A=⎝⎛0−1010000e−ikv⎠⎞N(U)=⎝⎛0∫vfhdv−E∂vfh⎠⎞
avec comme condition initiale : f=(1−α)fc+αfh×(1+ϵcos(kx)). Pour fh nous prenons :
fh=M[α/2,u,1]+M[α/2,−u,1]
il est également possible de prendre :
fh=M[1,0,1]Sv10
où S est une constante de normalisation. Dans la pratique il est nécessaire dans le modèle de considérer la densité des particules froides ρc même si lors de la linéarisation celle-ci est considérer comme constante, et il y a une erreur de signe. Le modèle devient alors :
A=⎝⎛0−ρc010000e−ikv⎠⎞N(U)=⎝⎛0−∫vfhdv−E∂vfh⎠⎞
avec ρc=1−α en utilisant les notations des conditions initiales proposées.
Tout le document a été corrigé conformément à cette erreur.
Simulation
Nous avons opté pour la comparaison entre 2 méthodes de simulation pour étudier ce modèle :
Méthode de Lawson, avec résolution du terme E∂vfh par WENO5
Méthode de splitting à 3 étages, avec résolution de l’équation ∂tfh+E∂vfh=0 par une méthode semi-lagrangienne d’ordre 5 dans un premier temps, avant d’utiliser une méthode WENO-SL.
Il existe un code opérationnelle pour la première méthode ainsi que la deuxième (avec un polynôme de Lagrange de degré 5).
J’ai enfin effectué un nouveau commit sur GitHub pour avoir une sauvegarde de mon code. Ces codes s’y trouvent.
J’ai donc maintenant 3 codes de simulation de Vlasov-Poisson :
un code full cinétique avec Lawson+WENO
un code hybride avec Lawson+WENO
un code hybride avec splitting à 3 étages
2019-12-12
Étudions le WENO-SL présenté par Qiu et Shu dans [Qiu:2011]. Il s’agit d’une méthode volumes finis semi-Lagrangienne. Pour cela on s’intéresse à l’équation :
ut+(au)x=0
On commence par une intégration sur [tn,tn+1] :
u(tn+1,x)=u(tn,x)−(∫[tn,tn+1]au(τ,x)dτ)x
soit :
uin+1=uin−Fx∣x=x1
où F est défini par :
F(x)=∫[tn,tn+1]au(τ,x)dτ=Δx1∫[x−2Δx,x+2Δx]H(ξ)dξ
Cela nous permet dans un premier temps de réécrire la dérivée par rapport à x de F (ce que l’on doit calculer pour écrire notre schéma en temps) comme une différence de flux (méthode des volumes finis) :
Fx=Δx1(H(x+2Δx)−H(x−2Δx))
D’où l’écriture de :
uin+1=uin−Δx1(H(xi+21)−H(xi−21))
D’un autre côté, on intègre sur le domaine triangulaire Ωi défini par les trois points (xi,tn+1), (xi,tn) et (xi⋆,tn) (voir figure pour plus d’informations), l’équation de départ.
Domaine d’intégration Ω pour la construction de la méthode semi-lagrangienne
Le point xi⋆ est défini comme le pied de la caractérisitique issue de xi. Par intégration de l’équation sur Ωi :
∫Ωiut+(au)x=0
par le théorème de Green, on obtient directement (dans l’article ils utilisent le théorème de la divergence, mais je ne comprends pas alors comment est gérer le bord (xi⋆,tn),(xi,tn+1)) :
∫Ωiut+(au)x=−∫xi⋆xiu(tn,ξ)dξ+∫tntn+1au(τ,xi)dτ
ce qui nous donne :
∫xi⋆xiu(tn,ξ)dξ=∫tntn+1au(τ,xi)dτ=F(xi)
avec (méthode des volumes finis oblige) F(xi)=Hˉi (valeur moyenne de H sur la cellule [xi−21,xi+21]). Donc on utilise le pied exacte de la caractéristique xi⋆ pour faire une estimation du flux, on construit donc une méthode volumes finis semi-lagrangienne.
Il est nécessaire de reconstruire les {Hˉi}i=1N à partir des {uin}i=1N, plus précisemment les points nécessaires sont :
Hˉi=R[xi⋆,xi](ui−p1n,…,ui+q1n)
où R[a,b] est la reconstruction de ∫[a,b]u(t,ξ)dξ, en utilisant les points indiqués dans le stencil entre parenthèses. Le problème que l’on peut remarqué avec cette méthode volumes-finis/semi-lagrangienne est qu’il est nécessaire d’avoir tous les points entre xi⋆ et xi, aussi loin soit xi⋆. Dans la pratique, lors de l’écriture du schéma, seul le stencil autour de xi⋆ est nécessaire, mais pour conserver la formulation volumes-finis, il est nécessaire de considérer la reconstruction jusqu’à xi.
La suite de l’articule est tout un jeu de construction de l’opérateur de reconstruction R[a,b] en utilisant une méthode WENO, dans un premier temps avec xi⋆ dans la cellule [xi−1,xi] (volumes finis classiques), puis en dehors de cette cellule (avec la prise en compte de ξ=Δxxi⋆−xi⋆, donc un vrai WENO-SL).
Ce que j’ai pour le moment implémenté le 2019-11-06 n’est que la version où xi⋆ est dans la cellule [xi−1,xi].
2019-12-17
Ça y est, le projet ponio (Python Objects for Numerical IntegratOr) est partagé sur pypi, il suffit donc maintenant d’effectuer :
pip install ponio
pour bénéficier des meilleurs outils d’analyse de méthodes Runge-Kutta !
J’ajouterai prochainement tous mes outils d’analyse de WENO (5 et 3) linéarisé, et potentiellement d’autres intégrateur en espace. Il s’agit d’une bibliothèque d’outils pour l’étude de la stabilité de l’équation d’advection :
ut+ux=0
Je pense faire une mise-à-jour majeur (ajout des outils d’analyse de von Neumann) pendant les prochaines vacances.
Préparation de simus de comparaisons
Maintenant que j’ai 3 codes de simulations de Vlasov :
Full-kinetic avec Lawson
Vlasov hybrid linearized avec Lawson
Vlasov hybrid linearized avec splitting
il faut comparer les résultats. Nicolas propose de faire des simulations avec un maillage très fin (surtout en vitesse) pour comparer le modèle full-kinetic avec les modélisations hybrides, et ne voir que l’erreur d’approximation du δ0(v) par une gaussienne. Pour cela on simule à t fixé (∼5 ou 10). La gaussienne doit être au moins représentée par une vingtaine de points pour être correctement représentée, donc :
Δv∼20Tc
avec Tc=10−4,10−3,10−2,10−1. Donc pour s’assurer d’avoir toujours le même Δv (et donc le même Δt), on prend Δv∼2010−4=5.0⋅10−4. On prend le Δt qui CFLise ce Δv :
Δt=σ∣∣En∣∣∞Δv
Pour le moment le code VHL avec Lawson utilise un RK(3,3), donc σ=1.433 et les premières simus donnent ∣∣En∣∣∞≤0.12, on obtient alors pour Δv, Nv et Δt :
Δv≈5.0⋅10−4Nv=Δv16≈32000Δt≈5.9⋅10−3
Ce qui nous donne environ 1700 itérations pour atteindre le temps final 10, mais avec un Nv très grand (le maximum que j’avais pris jusque là était 2048).
Comparaison des pas de temps maximaux possibles avec différentes températures et taille de la grille en vitesse.
Tc
Δv∼20Tc
Nv∼Δv16
Δt∼1.4330.12Δv
10−4
5.00⋅10−4
32000
5.97⋅10−3
10−3
1.58⋅10−3
10119
1.89⋅10−2
10−2
5.00⋅10−3
3200
5.97⋅10−2
10−1
1.58⋅10−2
1012
1.89⋅10−1
Il est intéressant de noter que les modélisations hybrides supposent Tc→0 mais n’imposent pas de raffinement de maillage. Il peut être intéressant de comparer les résultats avec Tc=10−4 (et la grille en vitesse que cela impose) et une grille bien plus grossière avec une modélisation hybride).
On souhaite, en plus de ces 4 simulations en full-kinetic, avoir les résultats sur au moins 1 des 2 codes de modélisation hybride, pour comparer les quantités :
le champ électrique (∑i∣Eiε(t)−Ei(t)∣2)1/2, il est donc nécessaire d’avoir des simulations avec les mêmes pas de temps.
la densité ρε(t) contre ρc(t)+ρh(t), sachant que ρh est directement donnée par fh, mais ρc est une donnée perdue du problème qu’il faut récupérer par l’équation de Poisson (avec Fourier).
le courant J=∫vfdv contre ρcuc+∫vfhdv
l’énergie totale H=∬v2fdvdx+∫E2dx, contre H=∫ρcuc2dx+∬v2fhdx+∫E2dx
Bref il faut stocker avec les mêmes pas de temps :
l’énergie électrique (une seule valeure par itéation)
l’énergie totale (une seule valeure par itération)
le champ électrique en fin de simu
la densité en fin de simu
le courant en fin de simu
2019-12-19
À propos des relations de dispersion
Considérons le modèle de Vlasov-Poisson :
{∂tf+v∂xf+E∂vf=0∂xE=∫Rfdv−1
On souhaite linéariser le systène autour d’un état d’équilibre f(t,x,v)=feq(v)+εg(t,x,v) :
{ε∂tg+vε∂xg+Edvfeq+εE∂vg=0∂xE=∫Rfeqdv+ε∫Rgdv−1
On peut normalisé en considérant que la densité de particules à l’équilibre est de masse 1, par conséquent, l’équation de Poisson implique que E est de taille ε, on notera alors E(t,x)=εe(t,x) :
{ε∂tg+vε∂xg+eεdvfeq+ε2e∂vg=0ε∂xe=ε∫Rgdv
en ne conservant que les termes d’ordre ε on obtient finalement :
{∂tg+v∂xg+edvfeq=0∂xe=∫Rgdv
On note avec un d droit la dérivée en v de feq car feq ne dépend que de v, c’est une notation usuelle en physique.
On peut maintenant appliquer les transformées de Fourier et de Laplace, qui peuvent se résumer comme suit :
∂x⋅→ik⋅∂t⋅→⋅∣t=0−iω⋅
On continuera à utiliser le même nom de variable après les transformées successives de Fourier et de Laplace.
On peut simplifier le calcul en prennant une condition initiale nulle dans la transformée de Laplace. Dans tous les cas cela mènera à la même fonction D(ω,k).
{ik(v−kω)g=edvfeq−g∣t=0ike=∫gdv
La première équation nous permet d’expliciter g :
g=k(v−kω)iedvfeq+k(v−kω)ig∣t=0
La seconde équation donne alors :
e=−ki∫k(v−kω)iedvfeqdv−ki∫k(v−kω)ig∣t=0dv
soit :
e=1−k21∫v−kωdvfeqdvk21∫v−kωg∣t=0dv
On notera alors e=D(ω,k)N(ω,k) avec :
N(ω,k)=k21∫v−kωg∣t=0dvD(ω,k)=1−k21∫v−kωdvfeqdv
Bien entendu on s’intéresse aux pôles de cette fraction, c’est-à-dire aux zéros de D(ω,k).
Calcul d’intégrales
Il est intéressant de calculer pour des cas classiques la valeur de D(ω,k), considérons alors 2 cas classiques :
feq(v)=Mρ,u,T(v)=2πTρe−2T∣v−u∣2
feq(v)=δu(v)
Dans ces 2 cas, nous calculerons ∫Rv−βdvfeqdv.
Cas d’une distribution maxwellienne
∫Rv−βdvMρ,u,T(v)dv=∫Rv−β−T(v−u)Mρ,u,T(v)dv=−T1∫Rv−β(v−β+β−u)Mρ,u,T(v)dv=−Tρ−Tβ−u∫Rv−βMρ,u,T(v)dv
On s’intéresse maintenant plus particulièrement à l’intégrale : ∫v−βMdv :
∫Rv−βMρ,u,T(v)dv=2πTρ∫Rv−βe−2T∣v−u∣2dv=2πTρ∫Rv−u+u−βe−(2Tv−u)2dv
on effectue alors le changement de variable z=2Tv−u, dz=2Tdv :
∫Rv−βMρ,u,T(v)dv=2πTρ∫R2Tz+u−βe−z22Tdz=2πTρ∫Rz+2Tu−βe−z2dz
On introduit alors la fonction de Fried-Conte :
Z:ζ↦π1∫−∞+∞z−ζe−z2dz
D’où :
∫Rv−βMρ,u,T(v)dv=2TρZ(2Tβ−u)
ce qui nous permet de donner une expression de notre première intégrale :
∫Rv−βdvMρ,u,T(v)dv=−Tρ(1+2Tβ−uZ(2Tβ−u))
Cas d’une distribution de Dirac
∫Rv−βdvδu(v)dv=−∫Rδu(v)dv(v−β1)dv=∫Rδu(v)(v−β)21dv
soit :
∫Rv−βdvδu(v)dv=(u−β)21
Tests numériques
On souhaite calculer quelques relations de dispersion pour différentes conditions initiales. En particulier nous souhaitons étudier le cas triple beams qui correspond à la condition initiale :
f(t=0,x,v)=M(1−α),0,Tc(v)+(Mα/2,u,1(v)+Mα/2,−u,1(v))(1+ϵcos(kx))
avec α la densité de particules chaudes, u la vitesse caractéristique des particules chaudes, et Tc un paramètre pris arbitrairement bas correpondant à la température des particules froides (Tc≪1). Il est possible de dérivée de l’équation de Vlasov-Poisson un modèle hybride linéarisé qui permet de réaliser des simulations avec le cas critique Tc→0 qui nécessite, dans le cadre cinétique, une grille en vitesse infiniment fine. Dans ce cas la condition initiale se réécrit :
f(t=0,x,v)=(1−α)δ0(v)+(Mα/2,u,1(v)+Mα/2,−u,1(v))(1+ϵcos(kx))
Pour obtenir feq depuis ces conditions initiales dépendant de x et v il suffit de supprimer la perturbation en x (c’est-à-dire prendre ϵ=0). On remarque alors que feq n’est qu’une somme de distribution maxwellienne et de Dirac, il suffit alors, par linéarité de l’intégrale, de reprendre les calculs d’intégrales précédents.
On obtient alors pour le cas cinétique la relation de dispersion :
DK(ω,k)=1−k21[−Tc1−α(1+k2TcωZ(k2Tcω))−2α(1+2kω−uZ(2kω−u))−2α(1+2kω+uZ(2kω+u))]
Et dans le cas hybride linéarisé :
DH(ω,k)=1−k21[(1−α)(ωk)2−2α(1+2kω−uZ(2kω−u))−2α(1+2kω+uZ(2kω+u))]
2020-01-10
Calcul de l’énergie au cours du temps :
E(t)=∬v2fdvdx+∫E2dx=E(0)
Dans le cas cinétique, f(t=0,x,v)=M1−α,0,Tc(v)+(Mα/2,u,1(v)+Mα/2,−u,1(v)), ce qui donne :
EK(t)=[(1−α)Tc+αu2+α]L
La perturbation avec le cosinus passe à la trape car par intégration sur tout le domaine en x cela donnera 0.
Dans le cas hybride linéarisé, f(t=0,x,v)=(1−α)δ0(v)+(Mα/2,u,1(v)+Mα/2,−u,1(v)), ce qui donne :
EHL=[αu2+α]L
D’où :
EK(t)−EHL(t)=(1−α)LTc
ce qui donne en version discrète :
EKn+O(Δtp)−EHLn+O(Δtq)=(1−α)LTc
avec p et q respectivement les ordres en temps de codes de résolution du modèle cinétique et du modèle hybride linéarisé. Donc pour p et q suffisamment grand on ne trace que (1−α)LTc. Il est intéressant de constater que l’erreur sur l’énergie est linéaire par rapport au produit ρcTc, avec ρc la densité des particules froides dans la condition initiale (1−α).
Obtention du modèle de Vlasov hybride linéarisé
Parce qu’on a refait le calcul avec Nicolas, car j’ai eu un problème pendant les vacances pour réobtenir ce modèle, et pour être certain de l’avoir quelque part.
On part du modèle de Vlasov-Ampère, avec 2 espères, les particules froides fc et les partiules chaudes fh :
⎩⎪⎪⎨⎪⎪⎧∂tfc+v∂xfc+E∂vfc=0∂tfh+v∂xfh+E∂vfh=0∂tE=−∫v(fh+fc)dv
Le travail s’effectue essentiellement sur fc pour l’écrire comme un modèle fluide à partir de grandeurs intégrales, on calcule donc les moments de la première équation :
∫R∂t(1v)fcdv+∫Rv∂x(1v)fcdv+∫RE∂v(1v)fcdv=0
de plus, on suppose que fc(t,x,v)=ρc(t,x)δuc(t,x)(v), ce qui nous permet d’obtenir :
{∂tρc+∂x(ρcuc)=0∂t(ρcuc)+∂x(ρcuc2)−ρcE=0
On obtient ainsi le modèle de Vlasov hybride non-linéaire :
⎩⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎧∂tρc+∂x(ρcuc)=0∂t(ρcuc)+∂x(ρcuc2)−ρcE=0∂tE=−∫vfhdv−ρcuc∂xE=∫fhdv+ρc−1∂tfh+v∂xfh+E∂vfh=0
Il est a noter que l’équation de Poisson (4e équation) est toujours vérifiée si on calcule le champ électrique E à l’aide de l’équation d’Ampère (3e équation) et que l’équation de Poisson est vérifiée par la condition initiale, on ne l’écrira plus par la suite et on supposera seulement que notre condition initiale vérifie Poisson.
On souhaite maintenant linéarisé ce problème autour de :
ρc(t,x)uc(t,x)E(t,x)=ρc(0)(x)+==ερc(1)(t,x)εuc(1)(t,x)εE(1)(t,x)
On obtient alors (en négligeant tous les termes quadratiques ou plus) :
⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧ε∂tρc(1)+ε∂x(ρc(0)u(1))=0ερc(0)∂tuc(1)−ερc(0)E(1)=0ε∂tE(1)=−∫vfhdv−ερc(0)uc(1)∂tfh+v∂xfh+E(1)∂vfh=0
La première équation est la seule faisant intervenir ρc(1), il ne sert pas pour le calcul des autres variables et il peut être réobtenu par l’équation de Poisson (qui est toujours vérifiée si la condition initiale la vérifie), on retire donc de notre modèle cette première équation ainsi que cette variable. On remarque que les autres équations ne font intervenir que des termes d’ordre ε (fh étant supposé petit par rapport à fc), on peut donc simplifier par ε pour obtenir le modèle de Vlasov hybride linéarisé :
⎩⎪⎪⎨⎪⎪⎧∂tuc(1)=E(1)∂tE(1)=−∫vfhdv−ρc(0)uc(1)∂tfh+v∂xfh+E(1)∂vfh=0
Tracer EK(Tc) (pour voir une jolie droite). Pour cela choisir un temps arbitraire et faire une interpolation de Lagrange d’ordre 5 pour avoir pour chaque Tc le même temps.
Faire la même chose avec les autres grandeurs que l’on suit au cours du temps Emax et l’énergie électrique.
Faire des tests à produit ρcTc constant (donc différents α).
Vérifier avec les solutions des relations de dispersion et tracer ωK(Tc)−ωHL en fonction de Tc
Implémenter DP5 pour le VHLL (Vlasov Hybride Linéarisé avec Lawson), et commencer à regarder le pas de temps adaptatif.
Comparaison splitting - Lawson VHL sur l’énergie totale et tester avec des grands Δt (test de stabilité). Il est à noter que dans ce cas, Δv n’est pas imposé par Tc et peut donc être pris grand.
Résultats
Les courbes suivantes sont issus de l’interpolation de données au temps t1=9.5.
Évolution de l’énergie totale H en fonction de la température Tc
La pente de 10 concorde avec ce qui est attendu, α=0.2 et L=4π, donc (1−α)L≈10.05.
Évolution de Emax en fonction de la température TcÉvolution de l’énergie électrique en fonction de la température Tc
On peut aussi comparer les zéros des relations de dispersion entre le modèle cinétique (pour différentes valeurs de Tc) et celle du modèle hybride, on trace ainsi Δωc=ωK(Tc)−ωHL.
Attention : pour bien observer une droite la température Tc a été prise sur un domaine plus grand.
Différence des zéros de la relation de dispersion en fonction de la température Tc
On représente aussi l’erreur relative faite sur l’énergie totale. Le code cinétique donne, quelque soit la température, une erreur relative sur l’énergie totale nulle, à l’inverse du code hybride (variation très faible).
Évolution temporelle de l’erreur relative
2020-09-03
Je travaille sur la résolution numérique du modèle :
∂tU=AU+F(U)
avec :
U=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡jc,xjc,yBxByExEyf^⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤
et :
A=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡0100−100−10000−1000000000000000Ωpe20000000Ωpe200000000000−ikvz⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤,F(U)=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡00iEyk−iExk−iByk+∫Rvx(f^)iBxk+∫Rvy(f^)∂…(f^)⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤
On souhaite écrire un schéma exponentiel (Lawson(RK(3,3)) pour résoudre ce problème, celui-ci s’écrit :
Il s’agit de la méthode Lawson induite par la méthode RK(3,3) de Shu-Osher (qui fait donc qu’un seul appel à la fonction non linéaire F par étage, ce qui permet de réduire la complexité temporelle du schéma, au détriment de la complexité spatiale).
Le calcul de eΔtA peut se faire de manière exacte (pour la valeur de Ωpe=2) :
Et plus généralement je n’ai pas de problème pour calculer l’exponentielle de cette matrice pour des valeurs particulière de Ωpe.
J’ai réussi à générer automatiquement quelque chose de proche du code C++ que je vais écrire à partir de ces expressions de schéma et matricielle, par exemple pour le premier étage :
Je n’ai pas réussi à retirer de l’expression sympy les 1.0*..., normalement le compilateur devrait les supprimer lors de la première étage de compilation, au pire je pourrais les retirer à la main. Les autres étages sont générés avec sympy de la même manière.
Vous aurez remarqué la présence des variables jcx[i] et jcy[i] non définies ailleurs, il s’agit de l’approximation de ∫Rvx∣yfdv, ainsi que de \partial_\dots(1.0*hfn[k_x][k_y][k_z][i] qui est toute la partie non linéaire sur f, faisant intervenir WENO, que je ne sais pas encore comment écrire. Mais l’autre chose que j’ai remarqué c’est que l’écriture de notre matrice A laisse sous-entendre que jc,x et jc,y seront résolus dans l’espace réel, mais le brassage dû à eA implique que ces variables sont des variables de Fourier. Puisque la transformée de Fourier est définie par :
f^(ξ,v)=∫Rf(z,v)e−i2πξzdz
on peut écrire que :
∫Rvx∣yf(z,v)dv=∫R∫Rvx∣yf(z,v)dve−i2πξzdz=∫Rvx∣y∫Rf(z,v)e−i2πξzdzdv=∫Rvx∣yf^dv
Bref tout pour se faire dans l’espace de Fourier sauf le transport en v (caché dans ∂…(f^)). N’y a-t-il pas moyen d’effectuer ce transport dans l’espace de Fourier, ce qui éviterait des transformées de Fourier et transformées inverses, ainsi que le dédoublement de la mémoire nécessaire pour effectuer ces opérations ? En tout cas, vu que la seule opération nécessitant des variables dans l’espace réel est une opération ne modifiant pas jc,x∣y, Ex∣y ou Bx∣y, je pense que lors de la simulation je vais directement travailler sur ces variables dans l’espace de Fourier (et faire les transformées inverses lorsque c’est nécessaire).
L’étape restante la plus problématique est l’appel au WENO en 3D, donc je pense que dans le courant de la semaine prochaine j’aurais mes premières simulations qui tourneront (ou à débuger…).
2020-09-07
Chaque étage se décompose de manière similaire, voici le détail pour le premier étage en pseudo-code.
Calcul des variables j^c,x(1), j^c,y(1), E^x(1), E^y(1), B^x(1) et B^y(1) :
calcul des intégrales ∫vxf^dv et ∫vyf^dv :
(j^h,x)i←∑kx,ky,kzvkxf^i,kx,ky,kzΔv
(j^h,y)i←∑kx,ky,kzvkyf^i,kx,ky,kzΔv
pour tout xi (code donné par sympy) :
j^c,x(1)←⋯
j^c,y(1)←⋯
E^c,x(1)←⋯
E^c,y(1)←⋯
B^c,x(1)←⋯
B^c,y(1)←⋯
Calcul de la variable f^(1) :
transformée inverse de f^n :
(f)i,kx,kz,kz←iFFT(f^⋅,kx,kz,kzn)i (boucle en vx, vy et vz)
calcul de l’approximation de (Ex+vyB0+vzBy)∂vxf+(Ey−vxB0+vzBx)∂vyf+(vxBy−vyBx)∂vzf :
où WENO est une fonction qui calcule une approximation de a∂xu(xi) en prenant en argument a et le stencil ui−3:i+3. Cette fonction WENO diffère de ce que j’avais déjà pu implémenter avant, car il s’agissait alors d’une fonction renvoyant le flux numérique f^i+21±. C’est-à-dire WENO(a,ui−3,ui−2,ui−1,ui,ui+1,ui+2,ui+3) est une fonction renvoyant l’approximation : a+Δxui+21+−ui−21++a−Δxui+21−−ui−21− donc les flux numériques sont calculés 2 fois, ce qui engendre des pertes en temps de calcul, mais un gain important en utilisation de la mémoire (puisqu’il n’est pas nécessaire de sauvergarder tous les flux numériques avant calcul des différences).
2020-09-26
Toy model
On travaille sur le toy-model de Nicolas. Dans la résolution du modèle hybride-linéarisé de Vlasov-Maxwell en 3dv-1dz on se retrouve dans l’équation de Vlasov avec un terme en (E+B×v)⋅∇vf, et l’idée de ce toy-model est d’inclure le plus possible de terme dans la partie linéaire du schéma de Lawson, ici le terme en B0 (composante en z du vecteur B=(Bx,By,B0)T).
{∂tf+(E+Jv)⋅∇vf=0f(t=0,v)=f0(v)
avec :
v=(vxvy)E=(ExEy)J=(0−110)
On pose g(t,w)=f(t,etJw), soit g(t,e−tJv)=f(t,v), avec w=(w1,w2). On obtient alors :
∂tg(t,w)=∂t(f(t,eetJw))=−E⋅∇vf(t,etJw)
(pour le détail des calculs voir le document de Nicolas) et :
∂tg(t,w)=−E⋅∇vf(t,etJw)
On veut maintenir construire notre équation que vérifie g :
on retrouve bien l’équation du document de Nicolas, avec comme condition initiale g(t=0,w)=f0(v). Après avoir faire un schéma sur gavec un schéma Runge-Kutta, om retrouve la solution sur f par : f(t,v)=g(t,e−tJv).
Implémentation du toy-model
Je souhaite effectuer différents tests sur une équation de transport (simulation avec arithmétique stochastique, ou comparaison entre une méthode de splitting avec de la lazy evaluation et sans, etc.) donc le code pour simuler ce toy-model je change le repère de coordonnées en (x,y) (plutôt qu’un (vx,vy) correspondant plus au cas 1dz-3dv).
Donc avec ces notations le toy-model devient :
{∂tu+(E+JX)⋅∇Xf=0u(t=0,x,y)=u0(x,y)
avec :
X=(xy)E=(e1e2)J=(0−110)
Ce qui nous donne la version filtrée suivante : ∂tg(t,z)=E⋅etJ∇zg(t,z) avec z=(z1,z2).
L’équation sur u est résolu avec une méthode Runge-Kutta, un RK(3,3) suffira pour le test, et l’équation sur g aussi. La CFL sur u est du type : Δt≤σ∥E+JX∥∞Δx, ce qui est grosso-modo une CFL en Δt≤σ∥E∥∞+xmaxΔx (on considère que domaine symétrie en x et y avec (x∣y)min=−(x∣y)max, la notation (x∣y) indique indifféremment la variable x ou y). La CFL de l’équation filtrée est, quant à elle, en Δt≤σ∥E∥∞Δx, la taille du domaine n’est plus impactée dans la CFL.
Dans le cadre de la simulation du modèle 1dz-3dv, on sait que E peut-être considéré comme petit.
2020-09-28
Questionnement de CFL
Pour mettre en place le toy-model j’ai commencé par coder un petit programme pour simuler l’équation :
ut+aux+buy=0
de manière suffisamment souple pour que a et b puissent être des vecteurs, ou des scalaires. Donc en particulier j’ai regardé le cas a=−y et b=x, pour obtenir une rotation (dans le sens trigonométrique si je ne dis pas trop de bêtises) :
∂tu−y∂xu+x∂yu=0
J’effectue la simulation sur un domaine carré, centré en (0,0), avec le même maillage dans la direction x et y. Sur cette équation, on s’était toujours dit que la CFL devait être en Δt≤σxmaxΔx, par analogie à une équation d’advection du type ut+aux=0 où la CFL est en Δt≤σ∣a∣Δx. Plus exactement la CFL est équivalente à considérer le splitting :
{∂tu−y∂xu=0{∂tu+x∂yu=0
où la CFL serait (si on résout chaque système avec une méthode de Runge-Kutta) en Δt≤min(σymaxΔx,σxmaxΔy).
Or… lorsque j’effectue une simulation avec cette CFL, cela explose. Puisque dans ma méthode Runge-Kutta je ne considère pas ce splitting, je résous l’équation suivante :
∂tu+J(xy)⋅∇u=0
où la CFL sera (par analogie au cas 1d) en :
Δt≤σ∥∥∥∥∥J(xy)∥∥∥∥∥?Δx
On a remarqué que prendre xmax, ce qui revient à prendre la norme ∥∥∥∥∥J(xy)∥∥∥∥∥∞ ne fonctionnait pas. Lorsque j’essaie de prendre la norme 2, donc 2xmax ça ne fonctionne pas non plus, je semble obligé de prendre 2xmax ce qui revient à prendre la norme 1.
Je n’ai pas réfléchi à pourquoi la norme 1, autrement qu’en remarquant que c’est la seule qui semble fonctionner dans mon problème. Je n’ai pas remis en question le calcul de mon nombre de CFL σ, calculé pour une équation 1d : ut+ux=0.
La question derrière tout cela étant aussi, comment cela se fait-il que je n’ai pas remarqué ce problème plus tôt ?
J’ai essayé d’implémenter le splitting en utilisant pour résoudre chaque sous-système une méthode Runge-Kutta RK(3,3), je m’attendais à ce que ça ne donne pas de bons résultats (j’ai un étirement de la solution plus qu’une rotation), mais je suis bien sous CFL en utilisant la condition CFL avec la norme infinie.
Sur cela, j’implémente la version toy-model, cela demande de préciser les variables a et b avec :
aij=e1−yj,bij=e2+xi
puis une autre version avec le filtrage :
a(t)=e1cos(t)−e2sin(t),b(t)=e1sin(t)+e2cos(t)
2020-09-30
Nouvelles du filtrage
Le toy-model a été implémenté, et pour effectuer la rotation de fin : f(t,v)=g(t,e−tJv) Nicolas m’a conseillé le splitting en 3 étapes de Joackim. Effectuer une rotation de t revient à calculer la solution h de l’équation ∂th+Jv⋅∂vh=0, h(0)=g(t) (dans notre cas).
ϕ1ϕ2ϕ3={∂th+v2∂v1h=0={∂th−v1∂v2h=0={∂th+v2∂v1h=0
et on a f(t)=ϕ3[tan(t/2)]∘ϕ2[sin(t)]∘ϕ1[tan(t/2)](g(t)). Chaque système est résolu par une méthode de Lagrange d’ordre 5.
On effectue une simulation du toy-model avec les paramètres numériques suivants :
Nx=Ny=200
Tf=20
Ω=[−5,5]×[−5,5]
f(t=0,x,y)=exp(−0.75x2−0.25(y−1)2)
Une première simulation sera effectuée sous la condition CFL de l’équation sur f, ce qui nous donne :
Δt≤σ∥E+Jv∥1Δx≈0.00637255
et une seconde sous la condition CFL de l’équation sur g :
Δt≤σ∥E∥1Δx≈0.325
Dans le cadre de WENO-RK(3,3) σ≈1.3.
Résultats de simulation pour f, g et f après filtrage, pour Δt=0.00637255Résultats de simulation pour f, g et f après filtrage, pour Δt=0.325
La solution calculée sur f dans le cas où Δt=0.325 ne donne que des nan, car on est complètement hors CFL, la solution sur g reste bonne en norme de l’oeil.
Par contre… la simulation hybrid1dx3dv_lawson.cc explose toujours alors que je semble être largement sous CFL. Actuellement tourne un run avec B0=0. Les simulations de jeudi dernier qui concordaient bien entre la méthode de Lawson et la méthode de splitting étaient sur un maillage grossier, sur un maillage plus fin je semble toujours hors CFL alors que Δt=5⋅10−3.
Est-ce que implémenter directement le filtrage pour le modèle hybride avec la méthode de Lawson ne permettrait pas de résoudre ce problème de CFL ?
Filtrage du hybride 1dz-3dv
J’ai lancé une simulation avec B0=0 pour vérifier qu’il n’y avait pas d’autres erreurs dans le code de Lawson, et comparer cela avec la méthode de splitting, cela tourne très bien sans explosé à cause d’une contrainte de CFL. Donc d’après Nicolas, puisque de toute façon on voulait effectuer ce filtrage, je passe à l’implémentation de filtrage sans que la méthode de Lawson ne tourne (ou plus exactement sans comprendre d’où vient ce problème de CFL).
Je reprends les calculs de Nicolas, on pose g(t,z,w,vz)=f(t,z,e−tB0Jv,vz) pour obtenir l’équation sur g qui est :
∂tg+vz∂zg−e−tB0JE⋅∇wg−Bg=0
avec Bg=(v×B)⋅∇vf (v=(vx,vy,vz)T). J’obtiens finalement, après calcul :
On a toujours une équation du type : ∂tu=−vz∂zu+velocity_v1∂v1u+velocity_v2∂v2u+velocity_vz∂vzu, donc en reprenant le pseudo-code du 7 septembre, cela revient à simplement modifier les valeurs des variables velocity_vi.
Attention : les velocity_vi dépendent maintenant du temps, il est donc important de prendre en compte les pas de temps de chaque étage dans la méthode Runge-Kutta.
L’autre modification à effectuer est dans le calcul des flux ∫vxfdv et ∫vyfdv qui deviennent respectivement ∫(w1cos(B0t)−w2sin(B0t))gdwdvz et ∫(w1sin(B0t)+w2cos(B0t))gdwdvz. Ceux-ci dépendent également du temps.
2020-10-02
Reprise du calcul de filtrage pour le modèle 1dz3dv
On rappelle l’équation des particules chaudes dans le modèle hybride 1dz-3dv :
Ce qui nous donne les valeurs de velocity_vx,y,z :
velocity_vxvelocity_vyvelocity_vz=Exc+Eys+vzBxs−vzByc=−Exs+Eyc+vzBxc+vzBys=−Bx(sw1+cw2)+By(cw1−sw2)
2021-03-18
des calculs dans la fonction de stabilité d’une méthode de Lawson matricielle
On étudie la résolution numérique de l’équation :
u˙=Lu+N(u)
Soit le schéma Lawson induit par la méthode RK(3,3) de Shu-Osher :
linéarisons (pour étudier l’ordre du schéma), c’est-à-dire considérons : N:u↦N⋅u. Si L et N commutent, alors on trouve un+1=eΔtL[I+ΔtN+2Δt2N2+6Δt3N3]un, mais ne supposons pas cela ici.
u(1)=[eΔtL+ΔteΔtLN]un
Plusieurs fois dans ce calcul il est possible d’effectuer des factorisations par (I+ΔtN), cela ne sera pas effectuer ici, car nous souhaitons développer le résultat, donc il ne sert finalement à rien d’effectuer ces jolies factorisation.
L’ordre est une notion asymptotique, que l’on obtient en linéarisant notre problème, il me semble donc normal de supposer que L et N commutent pour trouver formellement l’ordre 3 de la méthode.
Maintenant si on souhaite étudier l’erreur avec un approximant de Padé (ou un développement de Taylor peut-être dans un premier temps), je pense que l’on peut partir de la forme un+1=eΔtL[I+ΔtN+2Δt2N2+6Δt3N3]un où L et N commutent. Cela revient donc à étudier un+1=[eΔtL+O((ΔtL)⋯)][eΔtN+O(Δt4N4)]un. On remarque alors que l’on a fait disparaître tout le problème, car L et N commutant cela revient à un+1=eΔt(L+N)+O(…).
Le problème est que je ne sais pas comment analyser le cas non-commutatif dans le cadre général, qui semble évidemment plus intéressant.
2021-04-17
Grands principes de Padé-Lawson-Runge-Kutta
On s’intéresse à la résolution d’un problème du type :
u˙=Lu+N(u)
Pour cela on se propose d’utiliser une méthode de Lawson induite par une méthode de type Runge-Kutta RK(s,n), ici on se concentrera sur une méthode RK(4,4) qui forme les premiers étages de la méthode à pas de temps adaptatif DP4(3) :
Nous souhaitons utiliser cette méthode dans un contexte où le calcul de eαΔtL est compliqué formellement (i.e. avec sympy), nous nous proposons de réécrire ce schéma en substituant la fonction M↦eM par M↦Pp,q(M) pour l’approximant de Padé d’ordre (p,q) de eM.
Il est a noter que cette étape, d’un point de vue informatique, signifie simplement que l’on propose une autre implémentation de la fonction exp.
Le schéma devient (simple réécriture) :
u(1)u(2)u(3)un+1=Pp,q(2ΔtL)un+21ΔtPp,q(2ΔtL)N(un)=Pp,q(2ΔtL)un+21ΔtPp,q(2ΔtL)N(u(1))=Pp,q(ΔtL)un+ΔtPp,q(2ΔtL)N(u(2))=−31Pp,q(ΔtL)un+31Pp,q(2ΔtL)u(1)+32Pp,q(2ΔtL)u(2)+31u(3)+61ΔtN(u(3))
où la fonction Pp,q est définie comme :
hp.q(z)=i=0∑p(p+q−i)!(p+q)!(p−i)!p!i!zikp.q(z)=j=0∑q(−1)j(p+q−j)!(p+q)!(q−j)!q!j!zjez≈Pp,q(z)=kp,q(z)hp,q(z)
pour une matrice quelconque M, on a :
eM≈Pp,q(M)=hp,q(M)⋅(kp,q(M))−1
Le calcul des Pp,q(αΔtL) nécessite à chaque fois une inversion de matrice, ce qui a un coût numérique élevé. Une astuce consiste donc à considérer la fonction t↦P(t⋅L) et de l’évaluer en certaines valeurs pour t=αΔt. L’inversion n’est alors effectuée qu’une seule fois (lors de la construction de la fonction Pp,q[L]:t↦Pp,q(t⋅L). L’évaluation de cette fonction en une valeur quelconque de t (même un symbol comme Δt pour construire le schéma) est quasi-immédiate.
Maintenant pour générer un code C++ il suffit de convertir les expressions sympy ainsi obtenues en des chaînes de caractères représentant du code C++.
Cette étape se fait en plusieurs petites sous-étapes qui sont simplement techniques :
Conversion des symbols en des noms de variables C++, et conversion des fonctions mathématiques en des fonctions ayant pour nom leur équivalent C++ (sp.sin↦std::sin par exemple)
Évaluation des fractions (pour être sûr de ne pas avoir de division entre entiers qui donneraient 0 en C++ (1/2 == 0 et 1./2==0.5 par exemple).
Conversion en chaînes de caractères de ces expressions sympy (normalement le plus gros des manipulations sur les expressions est fait).
Mise en forme de ces expressions dans un squelette de code (utilisation de jinja2 qui est un moteur de template).
Et contrairement à ce que je m’attendais, ce sont finalement ces étapes qui prennent le plus de temps dans la génération de code, le calcul de l’approximant de Padé (ne s’effectuant qu’une seule fois) est relativement rapide.
Étude de l’approximant de Padé pour Vlasov-Maxwell hybride linéarisé
Dans cette section on se propose d’étudier le comportement de l’approximant de Padé pour l’équation de Vlasov-Maxwell hybride linéarisé (VMHL) :
L’opération de filtrage n’implique pas de grandes modifications dans l’implémentation, de plus celle-ci touche seulement l’équation de Vlasov sur la variable fh et le calcul des courants jh,⋆=∫v⋆fhdv, et ce que nous allons présenter ici touche très peu ces termes.
Ce système peut s’écrire sous la forme :
U˙=L(A00−ikvz)U+N(U)
Il est nécessaire dans un schéma de Lawson de calculer l’exponentielle de la partie linéaire L à différents temps. La matrice L est une matrice diagonale par blocs, et l’exponentielle d’une matrice diagonale est l’exponentielle des termes diagonaux, c’est-à-dire :
etL=(etA00e−ikvz)
Si on souhaite utiliser un approximant de Padé, il est possible de le faire seulement pour approximer etA, c’est-à-dire :
etL≈(Pp,q(tA)00e−ikvz)
Ceci permet de minimiser la taille de la matrice à inverser dans le calcul de Pp.q(M), minimiser la taille des expressions à manipuler avec sympy (espace mémoire et temps de calcul sur les arbres d’expression), et conserver exacte l’équation sur fh.
Maintenant nous nous proposons d’étudier le comportement de l’approximant de Padé, tout d’abord avec le choix de partie linéaire sans les équations de Maxwell, et ensuite avec les équations de Maxwell.
Partie linéaire sans les équations de Maxwell
Lorsque la partie linéaire ne contient pas les équations de Maxwell, la matrice de la partie linéaire L est :
L=⎝⎜⎜⎜⎜⎜⎜⎜⎜⎜⎛0B000−100−B00000−1000000000000000Ωpe20000000Ωpe200000000000−vz∂z⎠⎟⎟⎟⎟⎟⎟⎟⎟⎟⎞
Pour cette matrice sympy permet de calculer etL pour tout t et tout k (k intervenant dans la transformée de Fourier en z de la dérivée spatiale dans l’équation de Vlasov). Nous allons surtout étudier, pour B0=1 et Ωpe2=4, la matrice réduiteA, sans l’équation de Vlasov :
A=⎝⎜⎜⎜⎜⎜⎜⎜⎛0100−10−10000−1000000000000400000040000⎠⎟⎟⎟⎟⎟⎟⎟⎞
et regarder etA pour différentes valeurs de t et comparer Pp,p(tA) pour ces mêmes valeurs de t et différentes valeurs de p∈N.
Tout d’abord on regarde etA :
⎝⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎛0.378732187481834cos(22t9−17)+0.621267812518167cos(22t17+9)−0.378732187481834sin(22t9−17)+0.621267812518166sin(22t17+9)00−0.242535625036333sin(22t9−17)−0.242535625036333sin(22t17+9)−0.242535625036333cos(22t9−17)+0.242535625036333cos(22t17+9)0.378732187481834sin(22t9−17)−0.621267812518167sin(22t17+9)0.378732187481834cos(22t9−17)+0.621267812518167cos(22t17+9)000.242535625036333cos(22t9−17)−0.242535625036333cos(22t17+9)−0.242535625036333sin(22t9−17)−0.242535625036333sin(22t17+9)001.00000001.0000.970142500145332sin(22t9−17)+0.970142500145332sin(22t17+9)0.970142500145332cos(22t9−17)−0.970142500145332cos(22t17+9)000.621267812518166cos(22t9−17)+0.378732187481834cos(22t17+9)−0.621267812518166sin(22t9−17)+0.378732187481834sin(22t17+9)−0.970142500145332cos(22t9−17)+0.970142500145332cos(22t17+9)0.970142500145332sin(22t9−17)+0.970142500145332sin(22t17+9)000.621267812518167sin(22t9−17)−0.378732187481834sin(22t17+9)0.621267812518167cos(22t9−17)+0.378732187481834cos(22t17+9)⎠⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎞
à comparer avec P3,3(tA) :
⎝⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎛−5(64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000)2t2(3240t8−5985t6−48600t4−486000t2)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(1−2t2)(−7200t8−8460t6−151200t4−972000t2+3240000)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(−6t3+2t)(600t9−10170t7−32400t5−189000t3−1620000t)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(403t3−2t)(480t9−16200t7−64800t5−243000t3+1620000t)5(64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000)2t2(600t9−10170t7−32400t5−189000t3−1620000t)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(1−2t2)(480t9−16200t7−64800t5−243000t3+1620000t)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(−6t3+2t)(3240t8−5985t6−48600t4−486000t2)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(−403t3+2t)(−7200t8−8460t6−151200t4−972000t2+3240000)0030(64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000)t3(3240t8−5985t6−48600t4−486000t2)+10(64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000)t2(480t9−16200t7−64800t5−243000t3+1620000t)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(1−52t2)(600t9−10170t7−32400t5−189000t3−1620000t)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(24t3−2t)(−7200t8−8460t6−151200t4−972000t2+3240000)−30(64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000)t3(600t9−10170t7−32400t5−189000t3−1620000t)−10(64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000)t2(−7200t8−8460t6−151200t4−972000t2+3240000)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(1−52t2)(3240t8−5985t6−48600t4−486000t2)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(24t3−2t)(480t9−16200t7−64800t5−243000t3+1620000t)−5(64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000)2t2(600t9−10170t7−32400t5−189000t3−1620000t)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(1−2t2)(−480t9+16200t7+64800t5+243000t3−1620000t)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(−6t3+2t)(−3240t8+5985t6+48600t4+486000t2)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(403t3−2t)(−7200t8−8460t6−151200t4−972000t2+3240000)5(64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000)2t2(−3240t8+5985t6+48600t4+486000t2)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(1−2t2)(−7200t8−8460t6−151200t4−972000t2+3240000)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(−6t3+2t)(600t9−10170t7−32400t5−189000t3−1620000t)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(−403t3+2t)(−480t9+16200t7+64800t5+243000t3−1620000t)0030(64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000)t3(600t9−10170t7−32400t5−189000t3−1620000t)+10(64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000)t2(−7200t8−8460t6−151200t4−972000t2+3240000)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(1−52t2)(−3240t8+5985t6+48600t4+486000t2)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(24t3−2t)(−480t9+16200t7+64800t5+243000t3−1620000t)−30(64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000)t3(−3240t8+5985t6+48600t4+486000t2)−10(64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000)t2(−480t9+16200t7+64800t5+243000t3−1620000t)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(1−52t2)(600t9−10170t7−32400t5−189000t3−1620000t)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(24t3−2t)(−7200t8−8460t6−151200t4−972000t2+3240000)001000000100−5(64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000)2t2(1080t9−26370t7−97200t5−432000t3)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(1−2t2)(−2400t9+40680t7+129600t5+756000t3+6480000t)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(−6t3+2t)(−10440t8−2475t6−102600t4−486000t2+3240000)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(403t3−2t)(−12960t8+23940t6+194400t4+1944000t2)5(64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000)2t2(−10440t8−2475t6−102600t4−486000t2+3240000)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(1−2t2)(−12960t8+23940t6+194400t4+1944000t2)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(−6t3+2t)(1080t9−26370t7−97200t5−432000t3)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(−403t3+2t)(−2400t9+40680t7+129600t5+756000t3+6480000t)0030(64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000)t3(1080t9−26370t7−97200t5−432000t3)+10(64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000)t2(−12960t8+23940t6+194400t4+1944000t2)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(1−52t2)(−10440t8−2475t6−102600t4−486000t2+3240000)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(24t3−2t)(−2400t9+40680t7+129600t5+756000t3+6480000t)−30(64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000)t3(−10440t8−2475t6−102600t4−486000t2+3240000)−10(64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000)t2(−2400t9+40680t7+129600t5+756000t3+6480000t)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(1−52t2)(1080t9−26370t7−97200t5−432000t3)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(24t3−2t)(−12960t8+23940t6+194400t4+1944000t2)−5(64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000)2t2(−10440t8−2475t6−102600t4−486000t2+3240000)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(1−2t2)(12960t8−23940t6−194400t4−1944000t2)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(−6t3+2t)(−1080t9+26370t7+97200t5+432000t3)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(403t3−2t)(−2400t9+40680t7+129600t5+756000t3+6480000t)5(64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000)2t2(−1080t9+26370t7+97200t5+432000t3)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(1−2t2)(−2400t9+40680t7+129600t5+756000t3+6480000t)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(−6t3+2t)(−10440t8−2475t6−102600t4−486000t2+3240000)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(−403t3+2t)(12960t8−23940t6−194400t4−1944000t2)0030(64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000)t3(−10440t8−2475t6−102600t4−486000t2+3240000)+10(64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000)t2(−2400t9+40680t7+129600t5+756000t3+6480000t)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(1−52t2)(−1080t9+26370t7+97200t5+432000t3)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(24t3−2t)(12960t8−23940t6−194400t4−1944000t2)−30(64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000)t3(−1080t9+26370t7+97200t5+432000t3)−10(64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000)t2(12960t8−23940t6−194400t4−1944000t2)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(1−52t2)(−10440t8−2475t6−102600t4−486000t2+3240000)+64t12+864t10+11124t8+105705t6+394200t4+1458000t2+3240000(24t3−2t)(−2400t9+40680t7+129600t5+756000t3+6480000t)⎠⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎞
Valeurs propres de eA et comparaison avec les valeurs propre de Pp,p(A) pour p=1,…,14Comparaison de etA et Pp,p(tA) pour p=1,…,14 pour t∈[−1,1]. Ceci correspond à l’évaluation de eαΔtA pour des valeurs de α parfois négatives et un Δt<1, bref un cas classique dans un schéma de Lawson.
Étude préliminaire de l’approximant de Padé de la matrice réduite de la partie linéaire sans les équations de Maxwell
On remarque que les valeurs propres de la matrice Pp,p(A) convergent bien vers celles de eA, et qu’elles sont très proches numériquement à partir de n≥3. La norme (ici de Frobenius) de Pp,p(tA) converge bien vers celle de etA, et à partir de n≥10 l’erreur entre les deux est inférieure à l’erreur machine. Le paramètre t∈[−1,1] représente le pas de temps Δt. Les différents étages d’une méthode de Lawson basée sur RK(3,3) ou RK(4,4) demandent le calcul de eΔtA, e2ΔtA et e−2ΔtA (en tout cas dans les méthodes que je considère), de plus le pas de temps Δt est généralement pris petit (dans ce cas à cause de la CFL induit par les équations de Maxwell dans la partie non-linéaire), ce qui justifie t∈[−1,1].
La génération dans ce cadre là fonctionne sans nécessité d’assistance particulière à partir des fonctions de bases de sympy. Mais puisque j’ai rencontré des problèmes dans le contexte (qui est celui qui nous intéresse le plus) avec les équations de Maxwell dans la partie linéaire, j’ai re-coder une fonction de calcul de déterminant et d’inverse de matrice. Ces nouvelles fonction n’effectuent aucune vérification sur l’inversibilité de la matrice, pas de recherche de la meilleure ligne ou colonne pour effectuer le développement du déterminant, etc. Il s’agit d’implémentation naïves (M−1=detM1tcomA) mais qui tournent bien plus rapidement que leur équivalent sympy (qui font des vérifications sur la validité du calcul). Les expressions que j’obtiens ainsi sont très longues, donc leur traitement avec sympy est relativement long aussi.
Résultats numériques
Et maintenant des résultats de simulations sur le maillage Nz×Nvx×Nvy×Nvz=15×20×20×41, et Δt=0.1 avec une méthode Lawson-RK(4,4), et un approximant de Padé P2,2, bref normalement des conditions pas terribles pour faire tourner le schéma.
L’évolution temporelle de l’énergie électrique, magnétique et cinétique des particules froides
On voit que les résultats sont très semblables entre la méthode Lawson-RK(4,4) et la méthode Lawson-RK(4,4) avec approximant de Padé (2,2). La pente est bien capturée malgré le maillage. Ce résultat est confirmée avec l’erreur relative sur l’énergie totale, qui sont aussi très similaires.
L’évolution temporelle de l’erreur relative sur l’énergie totaleL’évolution temporelle de l’erreur entre les deux méthodes sur les différentes énergies
On peut tout de même mesurer une différence dans la résolution des deux méthodes, qui est de l’ordre de 10−7 jusqu’à 10−5 selon l’énergie considérée (ce ne sont pas des erreurs relatives !). Cette différence est simplement calculée en faisant la différence à chaque temps entre les deux énergies :
xexact Lawsonn−xPadeˊ Lawsonn,∀tn
avec x⋆n correspondant à une énergie (énergie électrique, énergie magnétique ou énergie cinétique des particules froides) au temps tn pour la méthode ⋆ (soit la méthode de Lawson exacte ou la méthode de Lawson avec approximant de Padé (2,2)).
J’ai un doute sur l’exactitude du résultat de la différence, car je me demande si je n’ai pas un problème de décalage sur la première itération. Dans tous les cas l’ordre de grandeur reste bon, et on observe bien la phase linéaire (où l’erreur est très faible), et la phase non-linéaire, où les champs sont plus important, ce qui pourrait expliquer la différence entre les méthodes.
Temps de calcul des simulation avec le maillage Nz×Nvx×Nvy×Nvz=15×20×20×41, et Δt=0.1.
Simulation
Temps de calul
LRK(4,4)
14h 30min 33s
P(2,2)-LRK(4,4)
14h 52min 28s
La différence de temps, sur une exécution, n’est pas significative, donc il ne semble pas y avoir de surcoût particulier à utiliser un approximant de Padé (en tout cas pour l’ordre faible).
Partie linéaire avec les équations de Maxwell
La matrice de la partie linéaire avec les équations de Maxwell est :
L=⎝⎜⎜⎜⎜⎜⎜⎜⎜⎜⎛0B000−100−B00000−1000000∂z00000−∂z00Ωpe200−∂z0000Ωpe2∂z0000000000−vz∂z⎠⎟⎟⎟⎟⎟⎟⎟⎟⎟⎞
De même pour ce cas nous allons considérer seulement la matrice réduiteA :
A=⎝⎜⎜⎜⎜⎜⎜⎜⎛0100−10−10000−100000ik0000−ik0400−ik0004ik000⎠⎟⎟⎟⎟⎟⎟⎟⎞
où les termes ik proviennent de la transformée de Fourier dans la direction z des dérivées spatiales.
sympy étant incapable de caluler etA pour une valeur de k donnée, tout les calculs seront entièrement réalisé avec numpy.
Pour différentes valeurs de k on trace dans un premier temps les valeurs propre de eA ainsi que celles de P3,3(A). On choisit l’approximant d’ordre 3, car les résultats sans les équations de Maxwell nous indiquent qu’à partir de p≥3, les valeurs propres de eA et Pn.n(A) sont numériquement très proches. J’aurai pu, par sécurité, prendre une valeur plus grande.
Valeurs propre de eA pour différentes valeurs de kValeurs propre de P3,3(A) pour différentes valeurs de k
Comparaison des valeurs propres de eA et de P3,3(A) pour différentes valeurs de k∈[[−Nz,Nz]].
On remarque que les valeurs propres sont bien sur le cercle unité, mais leur répartition est légèrement différente, cela est peut-être dû à l’ordre trop faible de P3,3.
On peut aussi tracer, comme pour le cas sans les équations de Maxwell, l’erreur entre etA et Pn,n(tA) pour t∈[−1,1] et p∈[[1,14]], j’ai fixé regardé ici 2 modes, k=2,15 (pas de raison particulière).
Erreur de Frobenius entre etA et Pp,p(tA) pour k=2Erreur de Frobenius entre etA et Pp,p(tA) pour k=15
Erreur entre etA et Pp,p(tA) pour deux modes k
Dans la pratique on choisit un approximant de Padé d’ordre particulier, ici ça sera 2 (choix purement arbitraire), et on regarde l’erreur entre etA et P2,2(tA) pour différents modes de Fourier k.
Erreur de Frobenius entre etA et P2,2(tA)
2021-04-21
À propos des valeurs propres de Padé
On souhaite s’assurer de la stabilité d’une méthode Padé-Lawson-Runge-Kutta, pour cela il semble nécessaire que les valeurs propres de Padé soient de norme inférieure ou égale à 1, pour se retrouver dans un cas similaire à la stabilité d’une méthode de type Runge-Kutta.
On commence l’étude par un approximant de Padé (2,2).
Module des valeurs propres de P2,2(A(k))
Numériquement dans ce cas, toutes les valeurs propres sont de module 1 (l’échelle est en 10−12+1), la monté en ordre dans l’approximant de Padé donne les mêmes résultats.
Module des valeurs propres de P3,2(A(k))
On remarque que si le numérateur est de degré plus élevé, l’approximant de Padé toutes les valeurs propres sont de module supérieur à 1 (la figure de droite n’est qu’un zoom proche de 1 pour observer le comportement de la ligne de valeurs propres visible à gauche). Cela implique l’instabilité d’une méthode induite par l’approximant de Padé P3,2, et on peut, sans problème généralisé pour tout n et m tels que n>m.
Module des valeurs propres de P2,3(A(k))
Dans le cas de l’approximant de Padé P2,3(A(k)), les valeurs propres de l’approximant de Padé sont toutes de module inférieur à 1, ce qui laisse sous-entendre la stabilité de la méthode de Lawson induite par cet approximant. On peut très certainement généralisé pour tout n et m tels que m>n.
Et parce que les figures sont jolies on peut aussi regarder la disposition des valeurs propres.
Valeurs propre de P3,2(A(k))Valeurs propre de P2,3(A(k))
Valeurs prorpres de P3,2(A(k)) (à gauche) et P2,3(A(k)) (à droite).
2021-07-09
Résultats Lawson approximé par Taylor ou Padé
Je fais ça rapidement, histoire de discuter des résultats numériques pour savoir ce que je garde vraiment ou non. À savoir que précédemment on a déjà illustré que les valeurs propres de la troncature de la série de Taylor ne sont (pas du tout) sur le cercle unité, alors que c’est le cas pour l’apporixmant de Padé. Cela fait dire à Nicolas qu’il faut tout bonnement le virer des résultats numérique, je trouve qu’il donne de meilleurs résultats qu’attendu (surtout lorsqu’on regarde les valeurs propres de T5(A)).
Je n’ai pas cherché à avoir de jolies explosions avec une rotation (même code que pour obtenir l’ordre des Lawson-Padé-Taylor mais en mode rotation). En effet ce code engendre des modes élevés (car multiplié par la vitesse qui dépend des bornes du domaine) et il est possible de faire exploser Taylor sans faire exploser Padé. Piste à creuser peut-être.
Vérification
Premier lot de runs, on utilise la même partie linéaire que dans le papier (donc les équations de Maxwell ne sont pas dans la partie linéaire). Il s’agit juste de vérifier la possibilité de la méthode.
Les énergies au cours du temps
Pour le moment rien de passionant, on cherche juste à vérifier que l’on peut approcher l’exponentielle de la partie linéaire sans encore en profiter (une proof of concept).
Recherche d’un plus grand Δt
Maintenant on met les équations de Maxwell dans la partie linéaire, on regarde si on peut prendre des pas de temps plus grand (des tests précédent m’ont fait remarquer que Δt=0.5 était un peu trop grand, on le confirmera après avec le pas de temps adaptatif). On prend le même Δt=0.05 que dans le papier, et un pas de temps plus grand Δt=0.1 qui devient intéressant.
Les énergies au cours du temps
Run pas très passionant non plus, ça marche, c’est cool !
Taylor
Exploration de différentes troncatures de la série de Taylor, de l’ordre 1 à 4, avec un RK(3,3). (Les runs précédent étaient avec un RK(4,4), il s’agit ici de faire des runs normalement plus rapide pour tester des trucs…)
Les énergies au cours du temps
On remarque que pour les Taylor d’ordre plus faible ça explose, je ne sais pas exactement pourquoi.
Padé
Exploration de différents approximants de Padé, de l’ordre (1,1) à (2,2), et il n’y a que le Padé (2,1) qui explose, ce qui s’explique parce que le numérateur a un degré supérieur au dénominateur.
Les énergies au cours du temps
Dormand-Prince
On regarde maintenant avec la méthode DP4(3), entre Taylor et Padé. On regarde tout d’abord les énergies, Padé prend de très grands pas de temps en début de simulation, ce qui explique le shift dans les résultats (la bonne solution est celle donnée par Taylor).
Les énergies au cours du temps
On regarde Maintenant l’historique de la taille du pas de temps, et on remarque que la méthode de Padé est nettement plus intéressante. Je présume que c’est le fait que Taylor soit, en théorie, instable qui justifie qu’il n’essaie pas de prendre de grands pas de temps, et se restreint à peu près à la CFL de la partie non-linéaire. On peut aussi regarder l’erreur locale, comme dans le cas du papier on a beaucoup d’itérations rejettées (je n’ai pas encore regardé en détail combien).
Les énergies au cours du temps
On peut regarder la contribution de chaque erreur, j’ai rassembler les courants froids, les champs magnétiques et électriques pour ne pas voir 7 contributions. On remarque que l’erreur provient très largement de E et de fh, ce qui correspond à ce qui est résolu dans la partie non-linéaire. Les blancs sont dûs aux itérations rejettées ou d’autres problèmes (purement techniques) de mon fichier de sauvegarde.
Les énergies au cours du temps
Par curiosité j’ai aussi regardé l’évolution du temps courant au cours des itérations.
Les énergies au cours du temps
2021-07-22
À propos des temps de calcul
Après un petit script bash pour récupérer les temps des simus, voici les résultats :
cas test
simu
temps
pade
vmhllf_mp11rk33
0d 05h 38m 50s
pade
vmhllf_mp21rk33
0d 05h 40m 19s
pade
vmhllf_mp22rk33
0d 05h 38m 29s
pade
vmhllf_mp12rk33
0d 05h 37m 47s
dtn
vmhllf_mp22dp43
0d 03h 49m 01s
dtn
vmhllf_mt5dp43
0d 06h 27m 39s
max/dt0p05
vmhllf_mp22rk44
0d 14h 13m 56s
max/dt0p05
vmhllf_mt5rk44
0d 14h 18m 13s
max/dt0p1
vmhllf_mp22rk44
0d 07h 09m 54s
max/dt0p1
vmhllf_mt5rk44
0d 07h 06m 30s
max/dt0p1
vmhllf_p22rk44
0d 07h 10m 59s
max/dt0p1
vmhllf_t5rk44
0d 07h 10m 07s
max/dt0p12
vmhllf_t5rk44
0d 05h 56m 46s
max/dt0p12
vmhllf_p22rk44
0d 06h 06m 08s
max/dt0p12
vmhllf_mt5rk44
0d 05h 58m 18s
max/dt0p12
vmhllf_mp22rk44
0d 05h 59m 38s
verif
vmhllf_rk44
0d 14h 10m 14s
verif
vmhllf_p22rk44
0d 14h 26m 49s
verif
vmhllf_t5rk44
0d 14h 21m 53s
taylor
vmhllf_mt4rk33
0d 05h 38m 29s
taylor
vmhllf_mt2rk33
0d 05h 37m 54s
taylor
vmhllf_mt3rk33
0d 05h 39m 09s
taylor
vmhllf_mt1rk33
0d 05h 38m 45s
Toutes les simus sont faites sur le maillage Nz×Nvx×Nvy×Nvz=27×32×32×41, jusqu’au temps final Tf=200. Les paramètres spécifiques aux cas tests sont (la valeur dt0 est la valeur du pas de temps initial, qui est le pas de temps pour toute la simu si la méthode n’est pas à pas de temps adaptatif) :
pade : dt0=0.1
dtn : dt0=0.1 (pas de temps adaptatif)
max/dt0p05 : dt0=0.05
max/dt0p1 : dt0=0.1
max/dt0p12 : dt0=0.12
verif : dt0=0.05
taylor : dt0=0.1
Le nom des simulations est formé de la manière suivante : vmhllf pour Vlasov Maxwell Hybride linéarisé Lawson filtré puis un m pour indiquer si Maxwell est dans la partie linéaire, puis la méthode d’approximation avec son ordre et enfin la méthode en temps rk33, rk44 ou dp43.
On compare que les simulations où le pas de temps était Δt=0.1 (pade, max/dt0p1/ et taylor), dans ce cas on remarque que le coup moyen par étage est de 1h45 (les simulations pade et taylor sont avec du RK(3,3) contre du RK(4,4) sur max/dt0p1). La seule simulation avec une méthode de Lawson standard est la simu verif avec vmhllf_rk44, et on remarque qu’il n’y a pas de surcoût significatif dans l’usage d’approximants de Padé ou de troncature de la série de Taylor.
J’ai lancé d’autres runs juste pour mesurer les temps de calcul sur le même cas test avec différents schémas, voici les résultats.
cas test
simu
(s)
temps
last time
chap3/time
vmhllf_mt5rk44
50403
0d 14h 00m 03s
200,00
chap3/time
vmhllf_mp22rk33
39326
0d 10h 55m 26s
200,00
chap3/time
vmhllf_mp22dp43
14984
0d 04h 09m 44s
200,00
chap3/time
vmhllf_mp11rk33
39251
0d 10h 54m 11s
200,00
chap3/time
vmhllf_mp22rk44
50399
0d 13h 59m 59s
200,00
chap3/time
vmhls_lie
48310
0d 13h 25m 10s
200,00
chap3/time
vmhls_suzuki
259173
2d 23h 59m 33s
191,75
chap3/time
vmhls_suzuki
270324
3d 03h 05m 24s
200,00
chap3/time
vmhllf_rk44
50775
0d 14h 06m 15s
200,00
chap3/time
vmhllf_dp43
42244
0d 11h 44m 04s
200,00
chap3/time
vmhls_strang
61794
0d 17h 09m 54s
200,00
chap3/time
vmhllf
41349
0d 11h 29m 09s
200,00
chap3/time
vmhllf_mt4rk33
39220
0d 10h 53m 40s
200,00
Le cas test est : Nz×Nvx×Nvy×Nvz=27×32×32×41 et Δt0=0.05 (pas de temps constant pour la majorité des simus, sauf la simu DP4(3) avec P(2,2) et la simu DP4(3) sans Maxwell dans la partie linéaire).
Pour la simulation avec Suzuki, le serveur de calcul PlaFRIM ne permet pas par défaut de lancer des jobs de plus de 3 jours, donc le temps indiqué pour la simulation Suzuki qui va jusqu’au temps 200 est une estimation.
Juste pour info j’ajoute aussi l’erreur relative sur ce cas test (les énergies sont toutes similaires et conforment aux relations de dispersion). On avait déjà remarqué que les méthodes de splittings n’ont pas encore convergées et donc n’ont pas le comportement souhaité en temps long. On observe 3 groupes de courbes :
en haut il y a la méthode de Suzuki (toute seule) qui, sans doute à cause des nombres FFT, a un comportement pire que Lie et Strang
au milieu il y a presque toutes les simulations
en bas, les simulations RK(3,3)-T(4) et RK(4,4)-P(2,2). Je n’ai pas d’explication du pourquoi. Ce sont deux simulations avec Maxwell dans la partie linéaire (ce qui augmente la conservation de quantités par la résolution exacte de nombreux termes).
Erreur relative des différentes simulations
Erratum : petite erreur dans l’ordre des données et leur label respectif dans la légende. Ce ne sont pas RK(3,3)-T(4) et RK(4,4)-P(2,2) qui sont en dessous, mais Lie et Strang ! (Suzuki reste bien au dessus) Toutes les méthodes de Lawson, avec ou sans Taylor ou Padé, avec ou sans pas de temps adaptatif, donnent la même erreur relative ou presque.
Erreur relative des différentes simulations
2021-07-29
Valeurs propres de Taylor
On souhaite calculer une approximation de l’exponentielle de la partie linéaire A de notre problème, où A est définie par :
A=⎝⎜⎜⎜⎜⎜⎜⎜⎛0100−10−10000−100000iκ0000−iκ0Ωpe200−iκ000Ωpe2iκ000⎠⎟⎟⎟⎟⎟⎟⎟⎞
avec les modes de Fourier κ∈[[−Nz,Nz]] et Nz=15, et Ωpe=2. On sait déjà que A étant semblable à une matrice anti-hermitienne, ses valeurs propres sont imaginaires pures.
On approche eM par une troncature de la série de Taylor à l’ordre m :
eM≈Tm(M)=k=0∑mk!Mk.
Les valeurs propres de A étant imaginaire pures, on sait que les valeurs propres de etA sont sur le cercle unité (∀t∈R).
Maintenant que tout est bien défini, regardons les valeurs propres de la troncature de la série de Taylor Tm(A), avec m=1,…,6.
Valeur propre de Taylor 1
Pour T1(A)=I+A, rien d’anormal puisque les valeurs propres de A sont imaginaires pures et que A est diagonalisable, on a :
I+A=P(I+D)P−1
où P est la matrice de diagonalisation de A. On trouve bien que les valeurs propres de I+A sont simplement translatées de 1.
Valeur propre de Taylor 2
Je n’y connais rien en géométrie et autres courbes quadratiques, mais ça me me semble pas étonnant de retrouver les valeurs propres T2(A) sur une parabole. On a aucune valeur propre dans le cercle unité pour Taylor 1 et 2.
Valeur propre de Taylor 3
Pour T3(A), on remarque que l’on a quelques valeurs propres (pour les modes les plus bas) dans le cercle unité, ce qui laisse présager d’une certaine stabilité du schéma de Lawson couplé à T3, ce qui… n’est pas ce que je retrouvais dans mes résultats numériques, où l’on remarque que le schéma de Lawson LRK(3,3) couplé à T1, T2 et T3 est instable. Après il y a assez peu de modes sur ou dans le cercle (en particulier le mode 2 (orange) qui risque d’être excité relativement tôt dans la simulation).
Énergie électrique, magnétique et cinétique des particules froides dans une simulation de Vlasov-Maxwell hybride linéariséValeur propre de Taylor 4
Pour T4 on a toutes les valeurs propres des bas modes dans le cercle unité, cela semble justifier de sa stabilité numérique observée dans l’exemple précédent.
Valeur propre de Taylor 5
Un peu la même chose pour T5, qui tourne sur de plus grosses simus (LRK(4,4) et avec un pas de temps plus grand que celui pris dans l’exemple précédent).
Valeur propre de Taylor 6
Et là, je pense que cela pourrait être intéressant d’ajouter une simu avec T6 car on remarque que les valeurs propres ne sont pas dans le cercle unité (elles en sont pas loin, comme pour T2 et T3), il semble donc possible d’avoir un schéma instable avec une méthode d’ordre plus élevé. Cela donnerait sans doute un dernier coup fatal contre l’utilisation de Taylor, actuellement on ne comprend pas pourquoi T4 et T5 sont stables (on allume suffisamment peu de modes, et pour ces quelques modes on est stable ?), mais illustrer que c’est instable avec T6 alors que l’on a une erreur de troncature plus faible me semble intéressant.
Une autre solution pour faire exploser toutes les simu avec Taylor est de rafiner un peu en z et utiliser une condition initiale excitée par un bain de modes. Sachant qu’on a pas besoin de capturer la pente, cela peut se faire avec un maillage grossier en vitesse.
2021-11-09
Lorsqu’il est question des points de Leja
Les points de Leja sont des points sélectionnés pour être pas trop mal pour mailler un domaine (le conditionnement du maillage est pas mauvais). Ce maillage n’est pas régulier et propose plus de points sur les bords du maillage qu’au milieu et on représente ici pour 11 points.
les 11 points de Leja sur l’intervalle [−100,100].
Le nième point de Leja d’un intervalle K est défini par :
zn=argz∈Kmax(V(z)=i=0∏n−1∣z−zi∣)
et z0 est pris tel que ∣z0∣=maxz∈K∣z∣. Ceci fonctionne donc sur le plan complexe ou un axe. Dans notre cas nous souhaitons principalement approcher la fonction exponentielle sur l’axe imaginaire, plus particulièrement en civjκΔt, avec les coefficients de Butcher ci∈[0,1] (généralement), la vitesse vj∈[−2,2]≈R, les modes de Fourier κ∈[[−13,13]] et le pas de temps Δt∈[0,4] (d’après mes simus à pas de temps adaptatif LDP4(3)-P(2,2)), soit l’évaluation de la fonction exponentielle sur l’axe imaginaire entre i[−100,100] environ. On construit donc le polynôme de Lagrange (de degré 10, car on a 11 points), et on va l’évaluer sur l’intervalle d’interpolation [−100,100] et regarder sa partie réelle (qui devrait être un cosinus) sa partie imaginaire (un sinus), son module (qui devrait être égal à 1), ainsi que placer ces points (qui devraient être sur le cercle unité.
Partie réelle de L10(iy) pour y∈[−100,100]Partie imaginaire de L10(iy) pour y∈[−100,100]Module de L10(iy) pour y∈[−100,100]Points sur le plan complexe L10(iy) pour y∈[−100,100]
Tests avec 11 points de Leja
Et on effectue la même chose pour faire du Lagrange d’ordre 5 (en théorie je devrais faire du Lagrange d’ordre 4 car je dois comparer ça avec du Padé (2,2).)
Partie réelle de L5(iy) pour y∈[−100,100]Partie imaginaire de L5(iy) pour y∈[−100,100]Module de L5(iy) pour y∈[−100,100]Points sur le plan complexe L5(iy) pour y∈[−100,100]
Tests avec 6 points de Leja
Forcément il y a quelque chose qui s’appelle le théorème de Shannon et le signal est ici très largement sous échantillonné
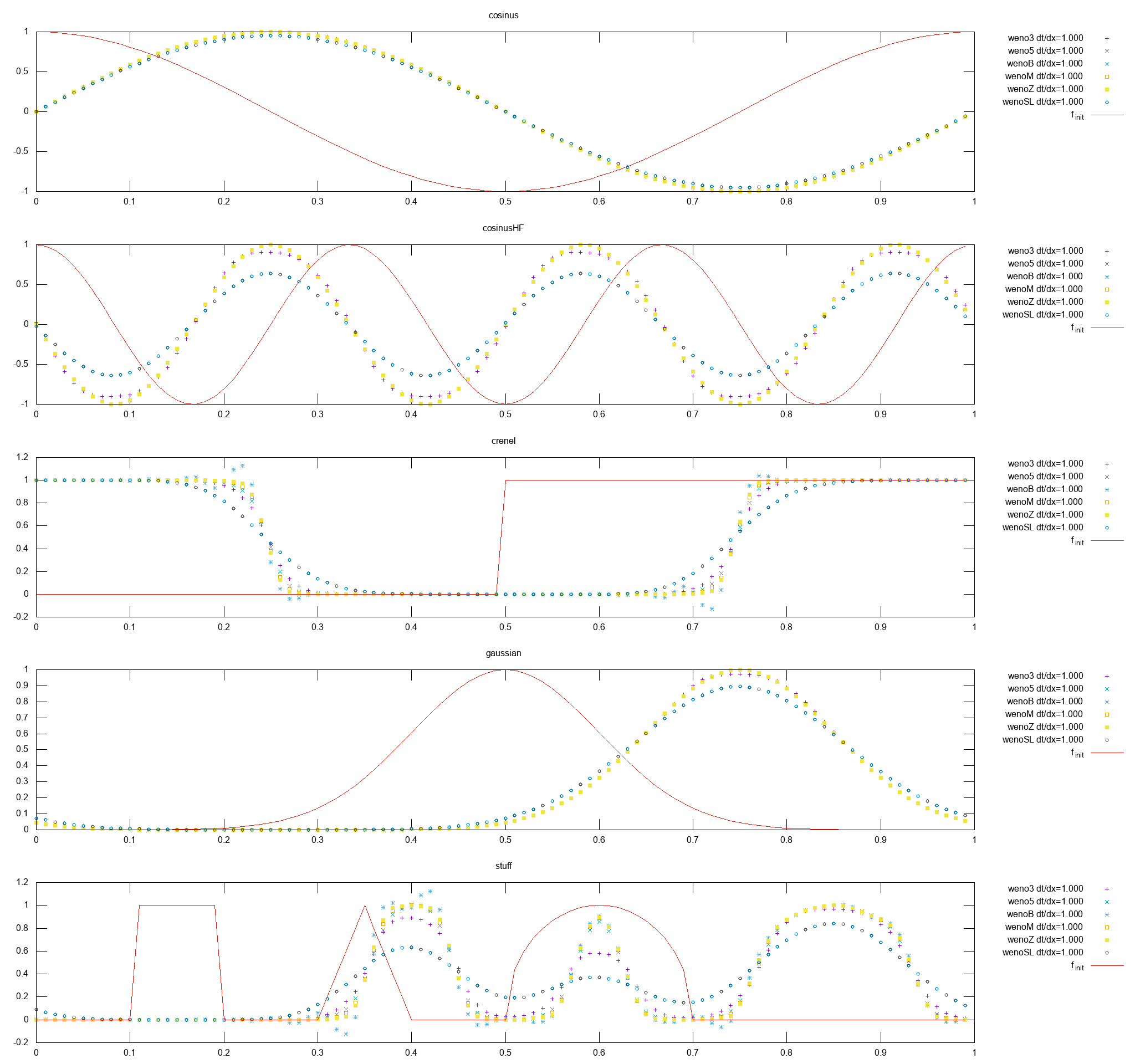
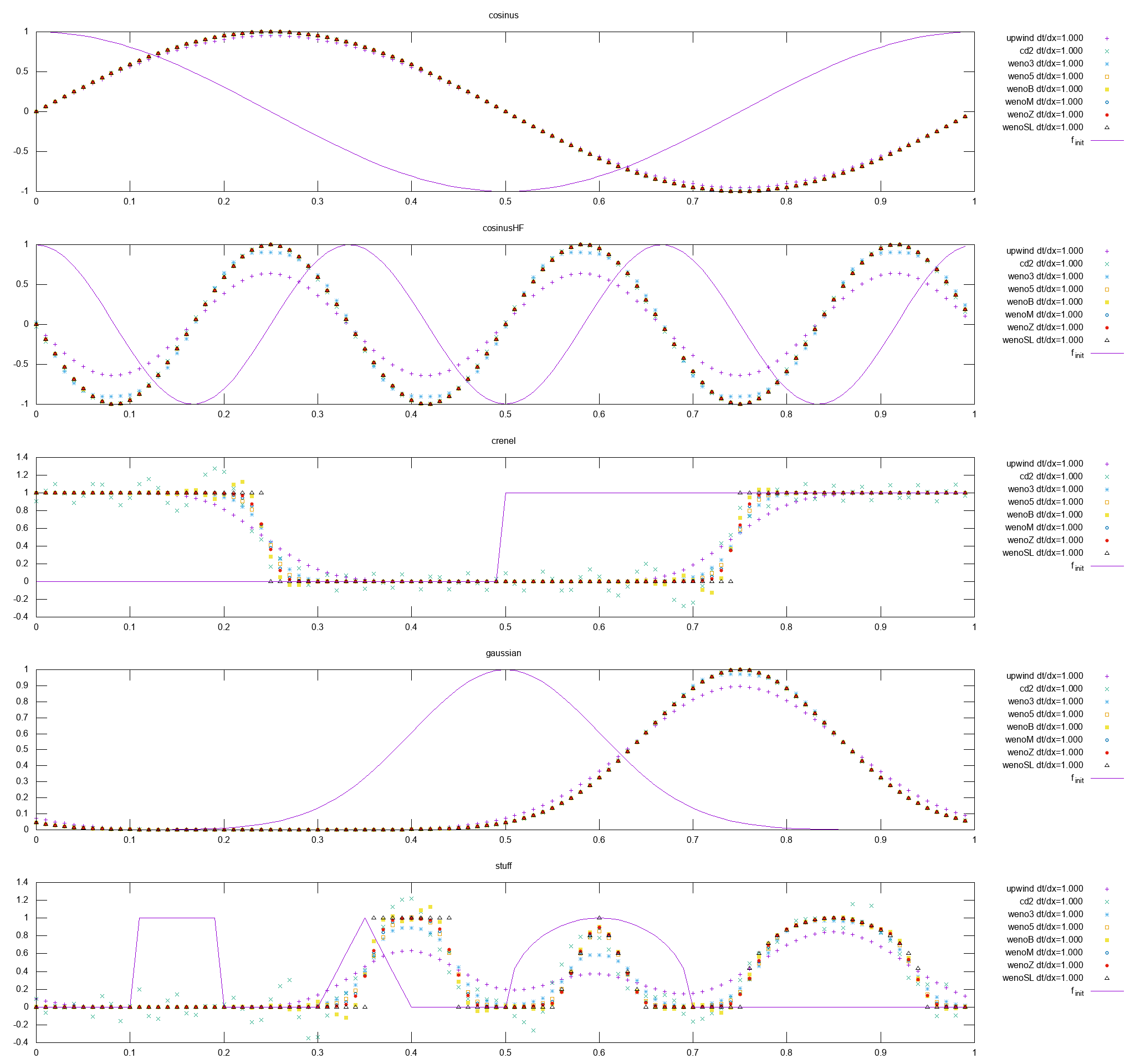
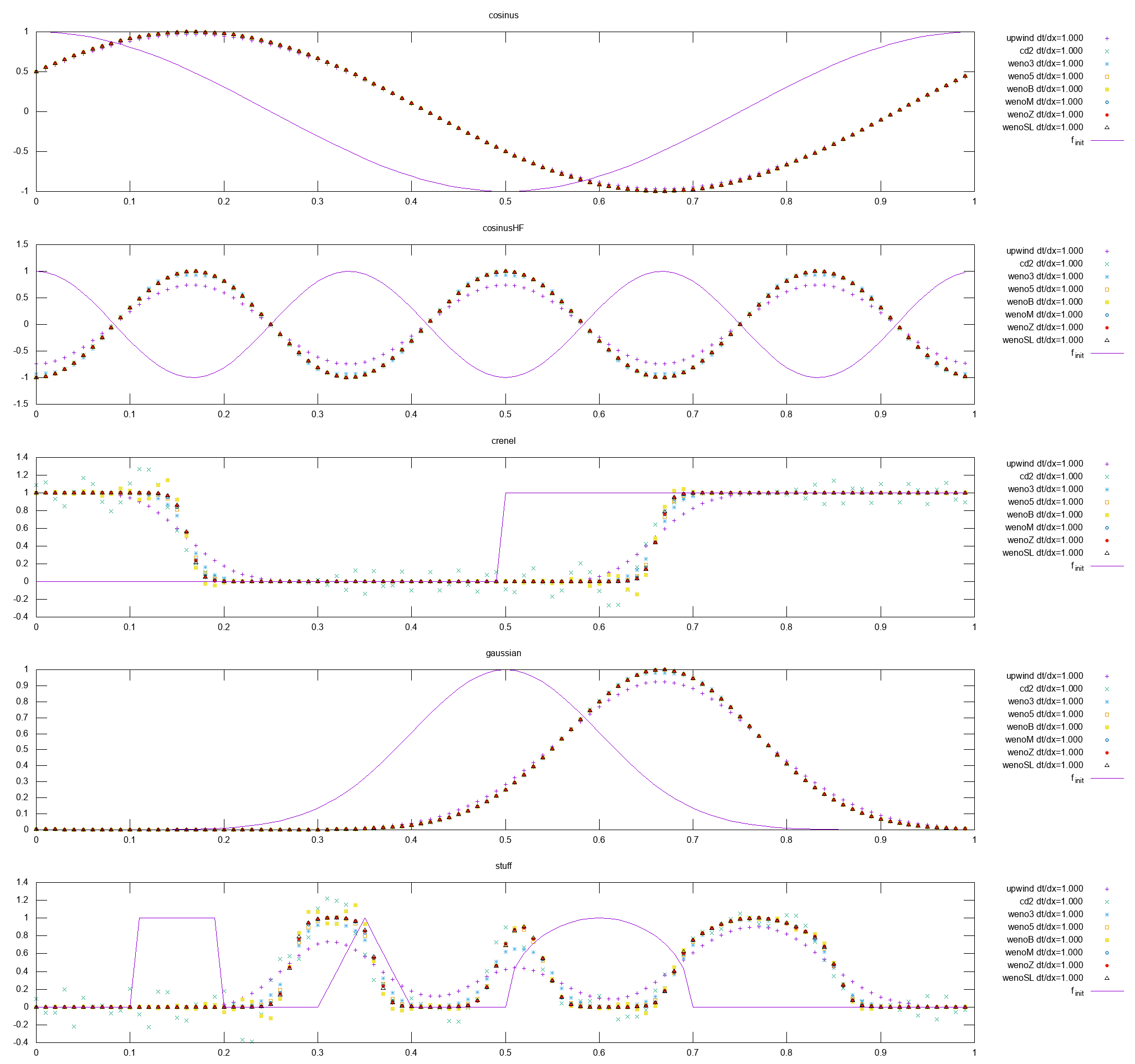
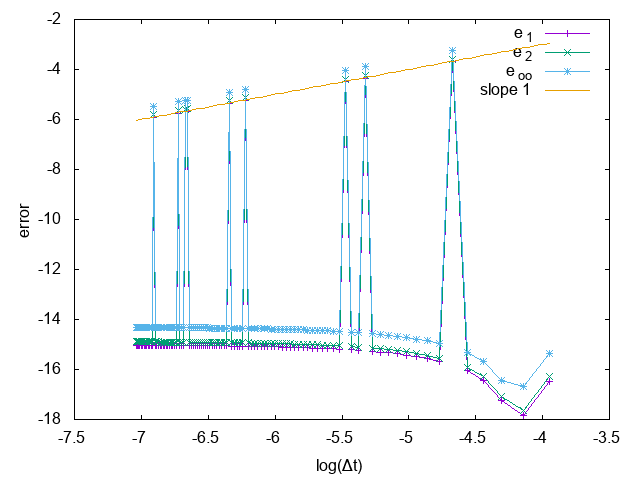
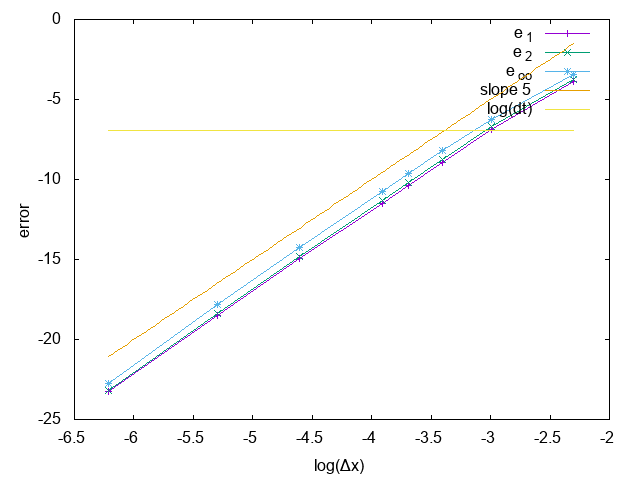
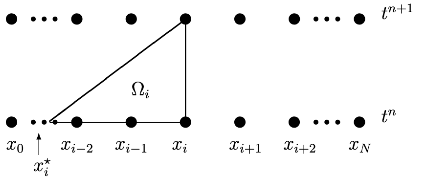
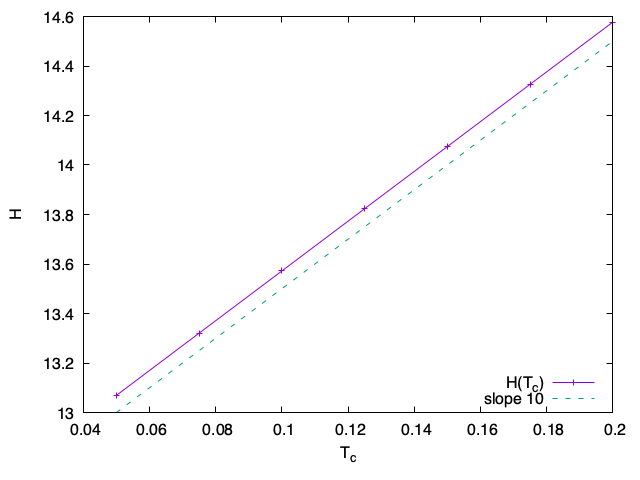
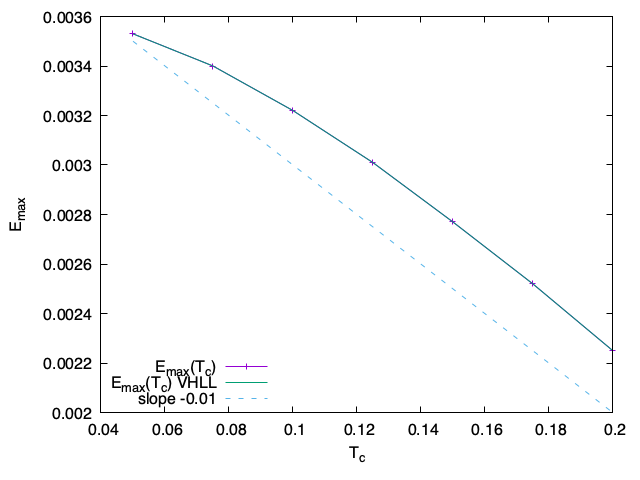
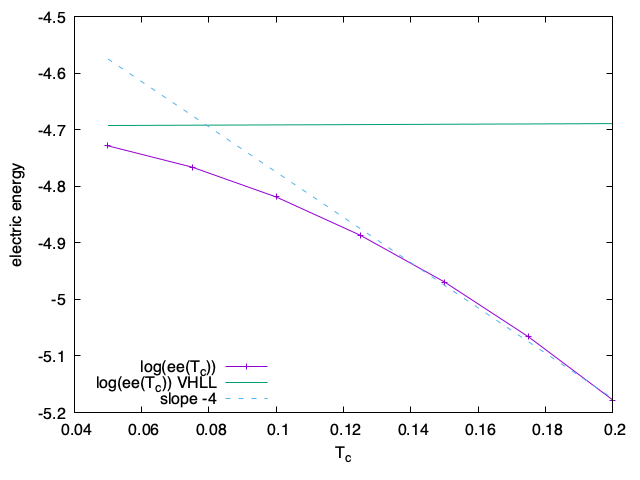
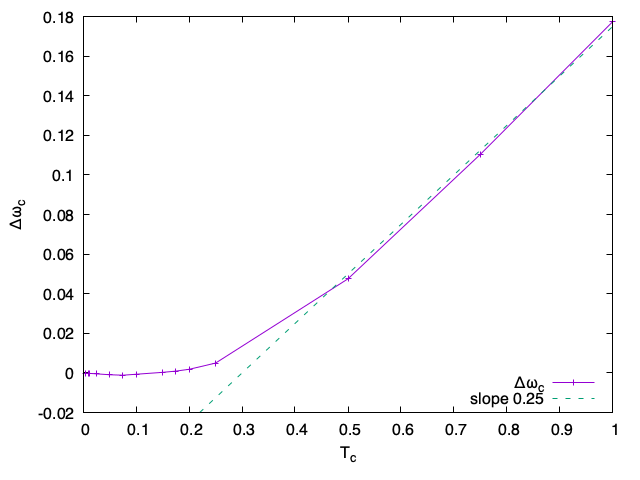
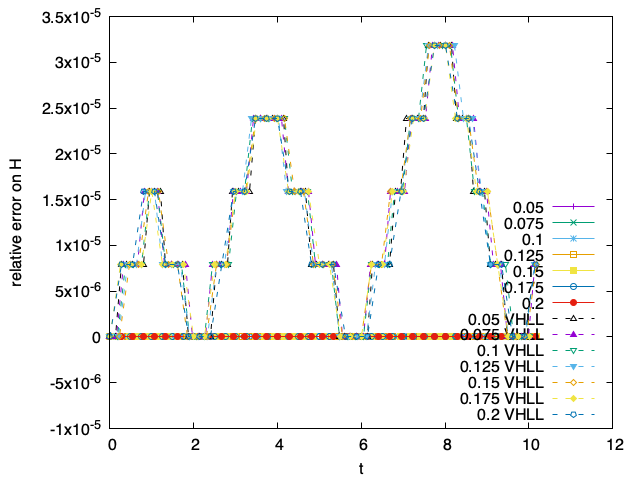
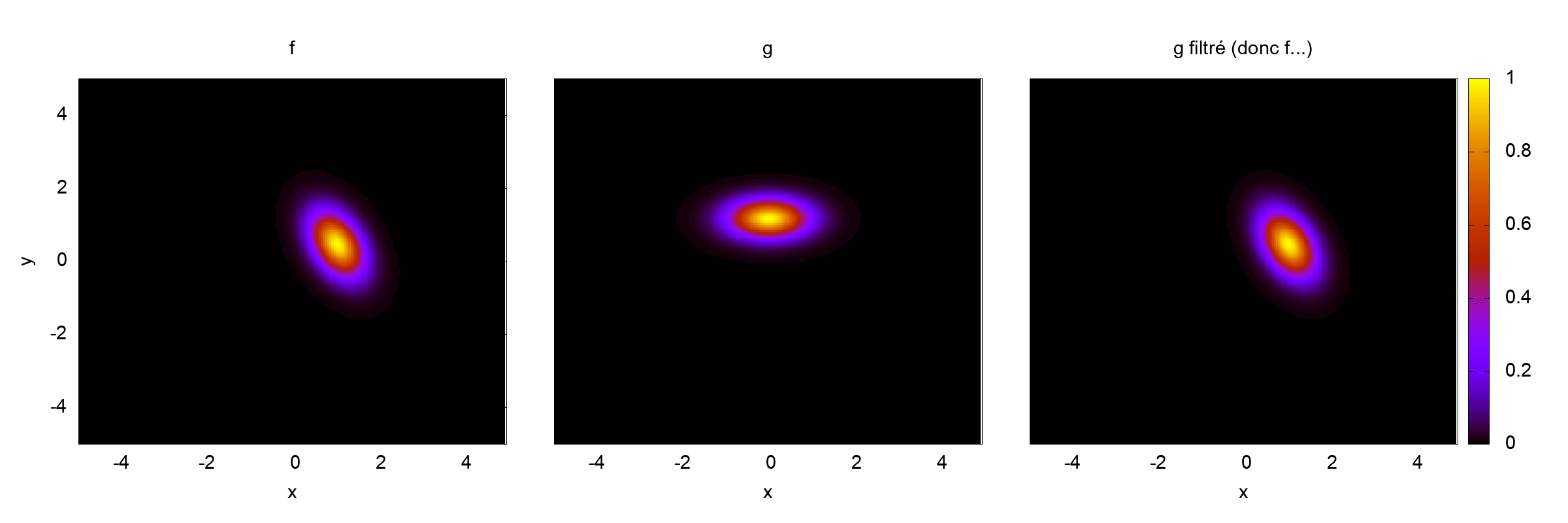
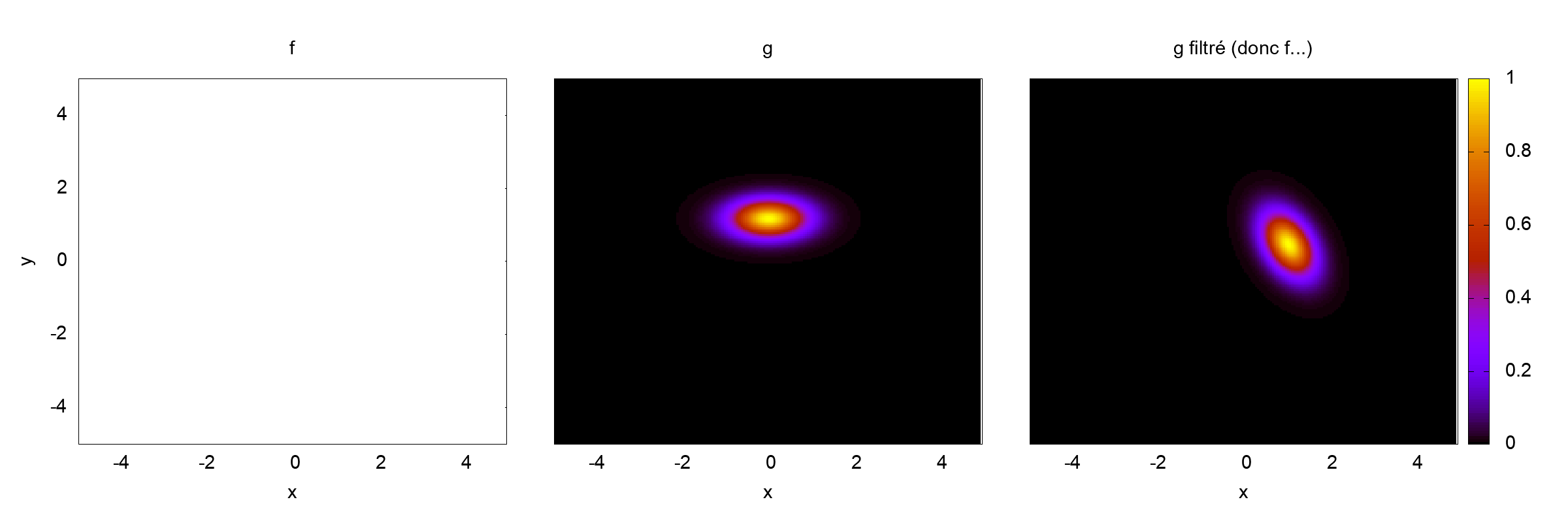
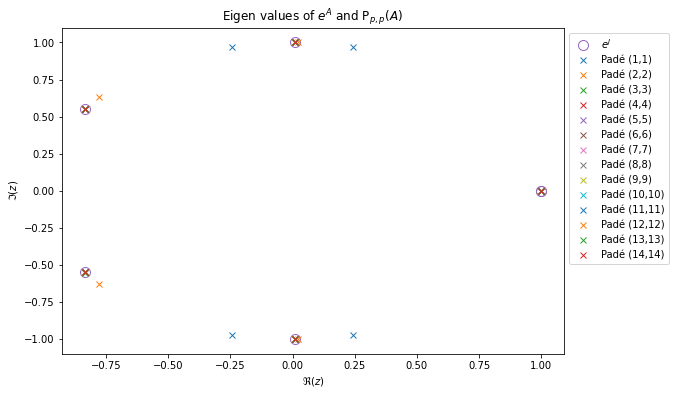
![Comparaison de e^{tA} et \mathrm{P}_{p,p}(tA) pour p=1,\dots,14 pour t\in[-1,1]. Ceci correspond à l’évaluation de e^{\alpha\Delta tA} pour des valeurs de \alpha parfois négatives et un \Delta t<1, bref un cas classique dans un schéma de Lawson.](img/fro_210417.png)
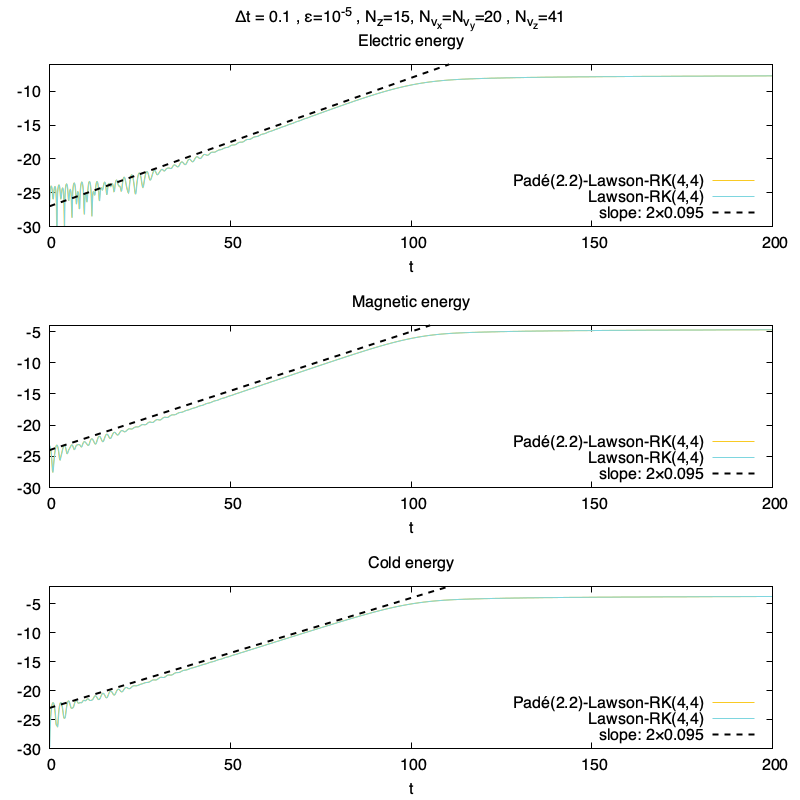
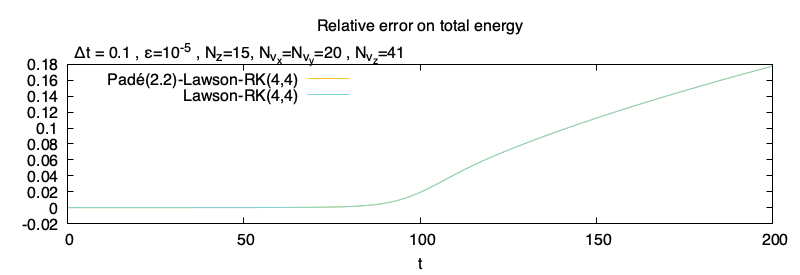
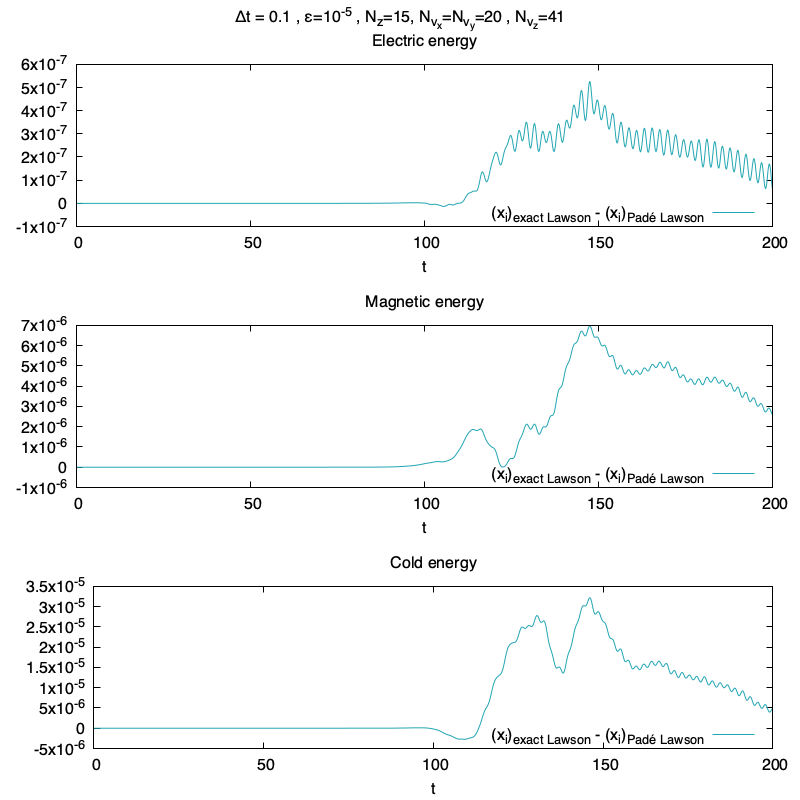
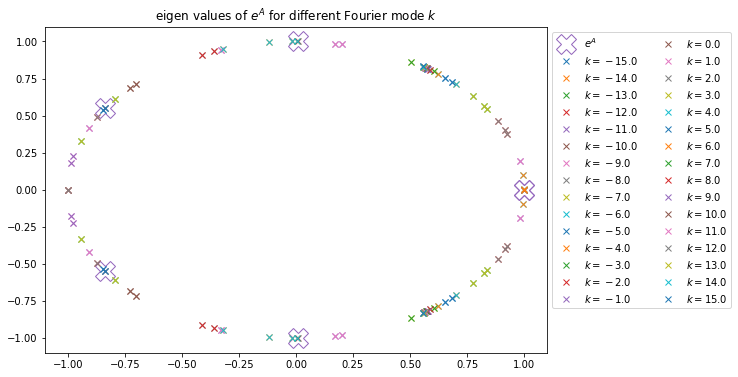
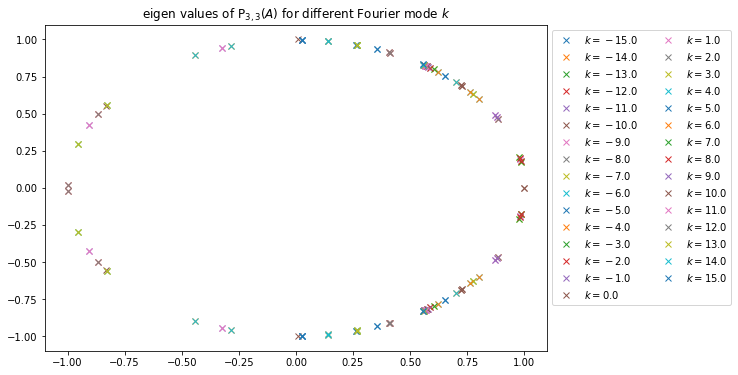
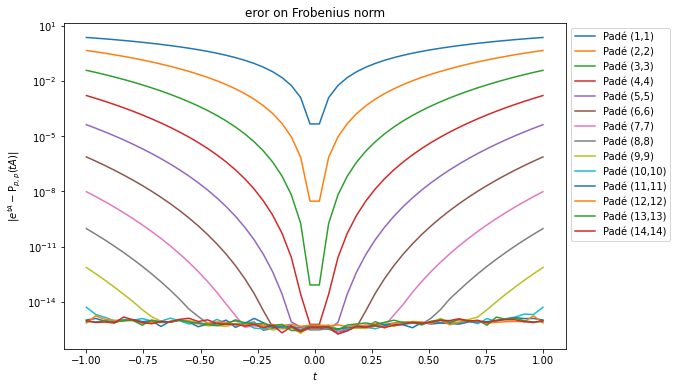
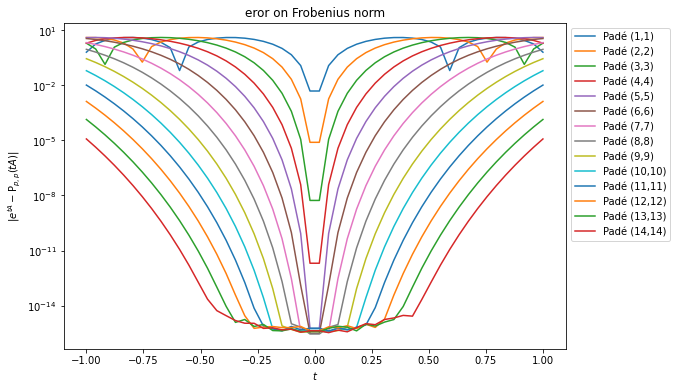
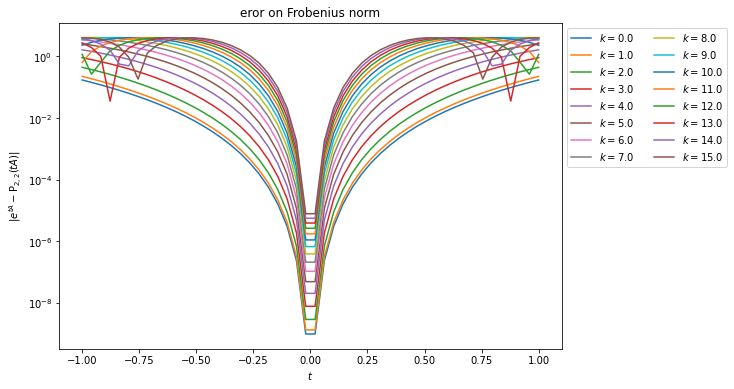

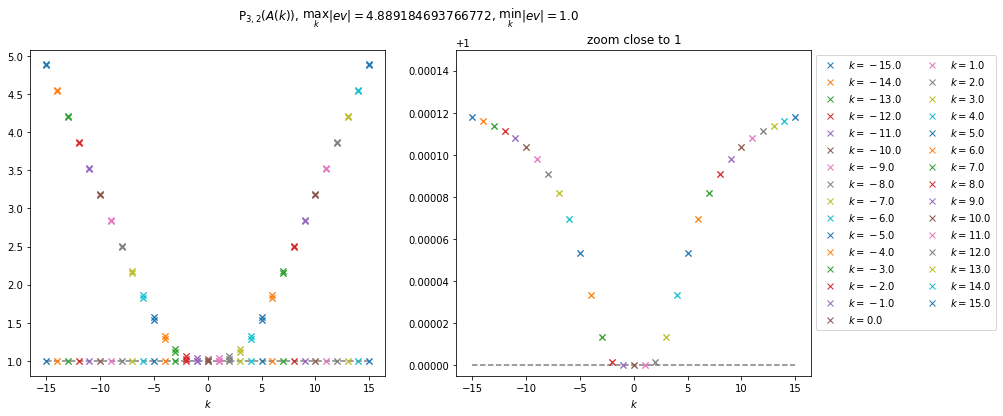
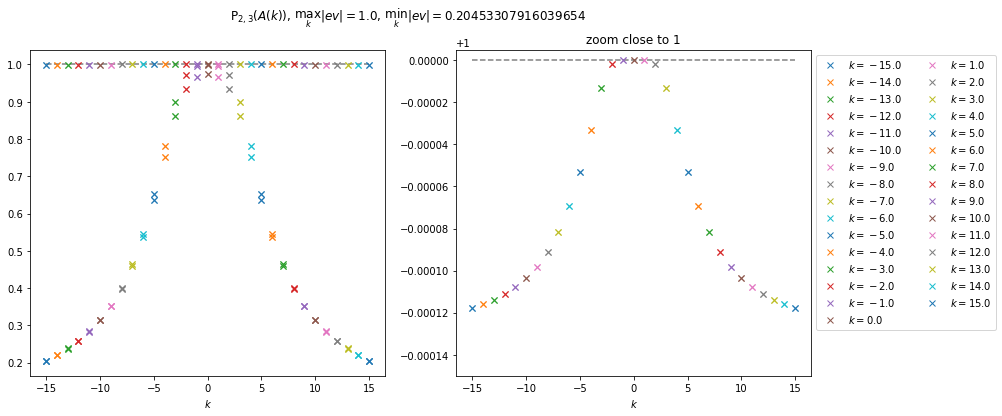
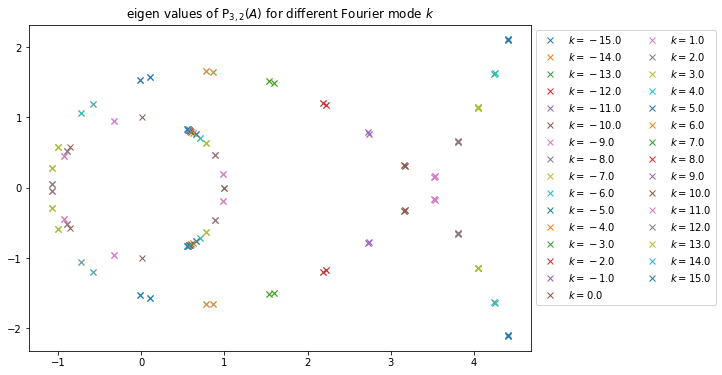
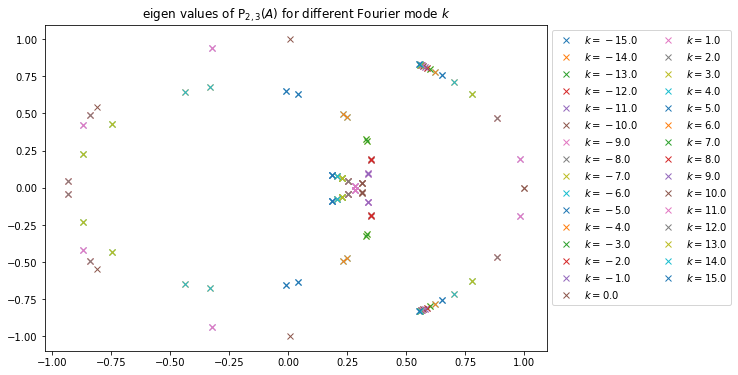
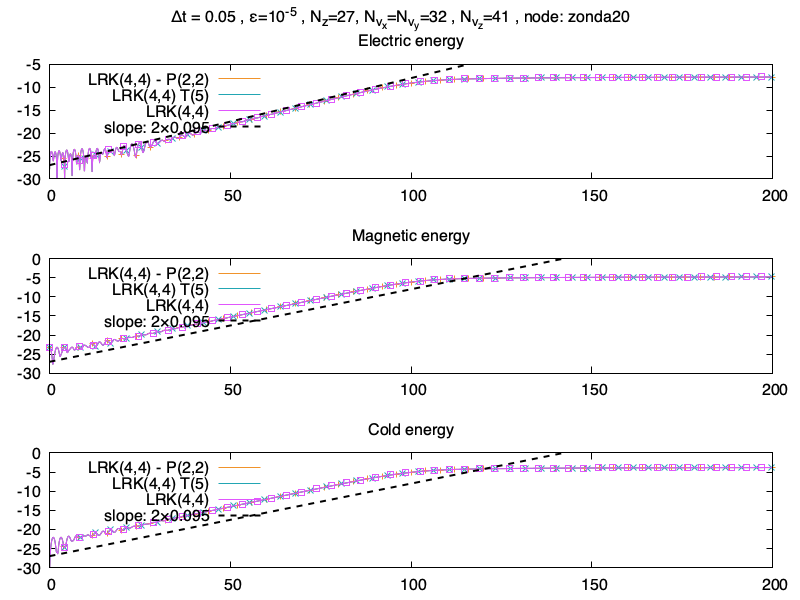
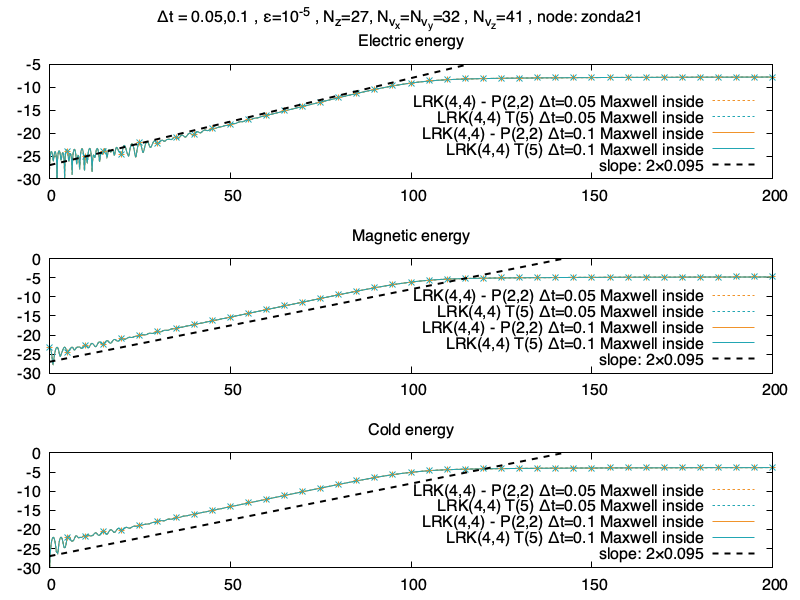
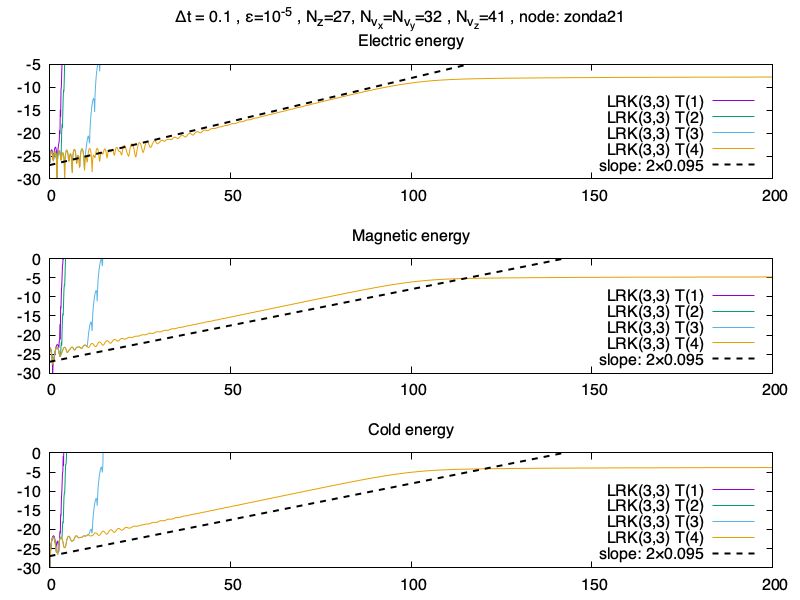
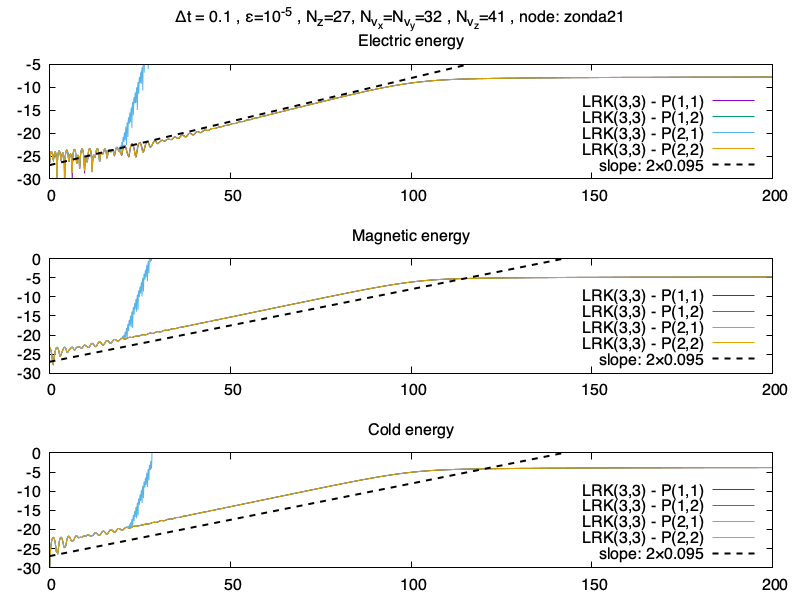
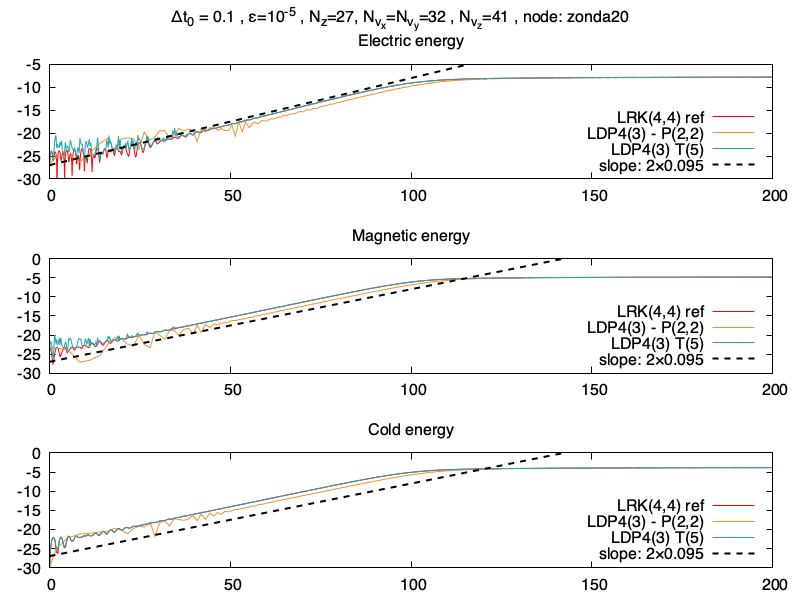
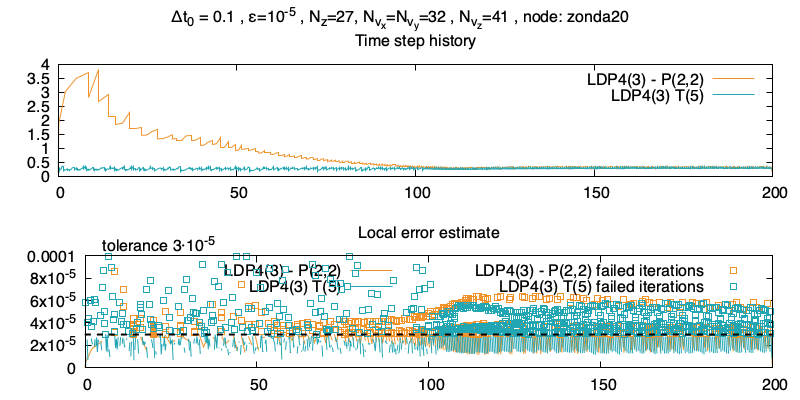
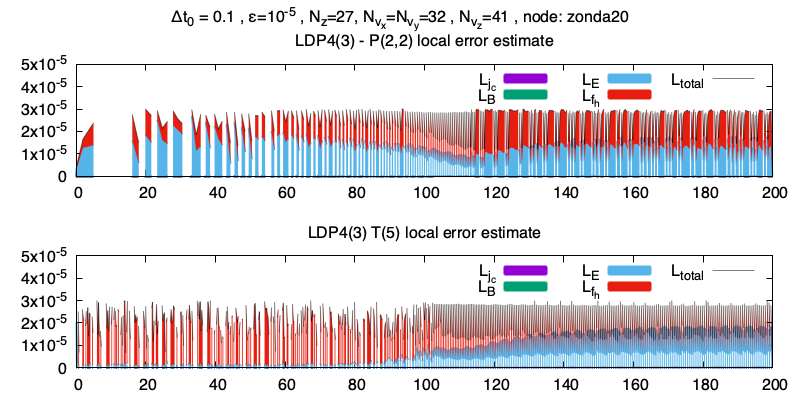
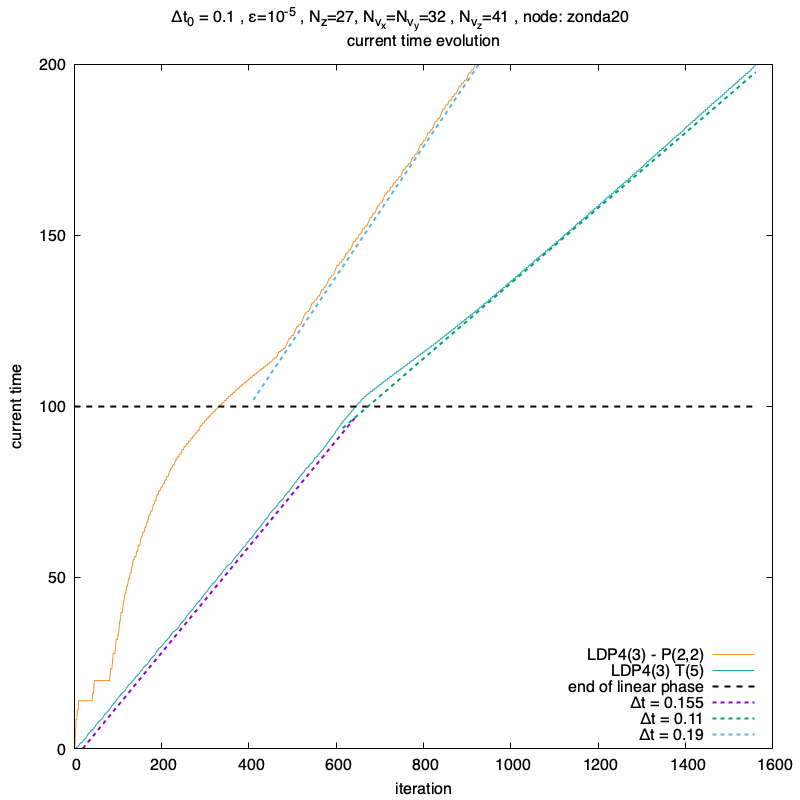
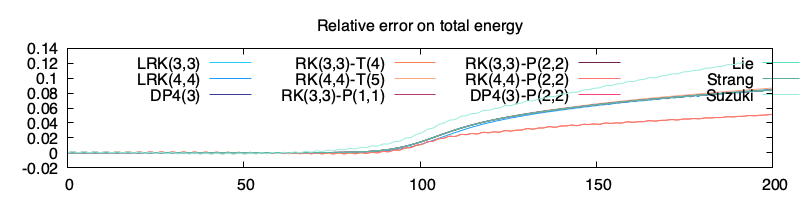
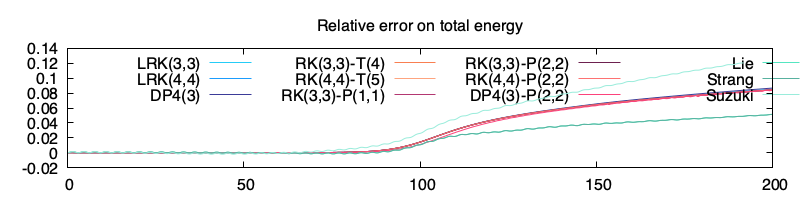
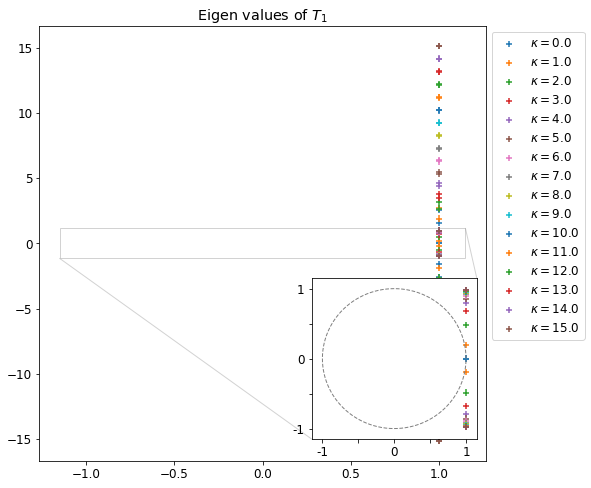
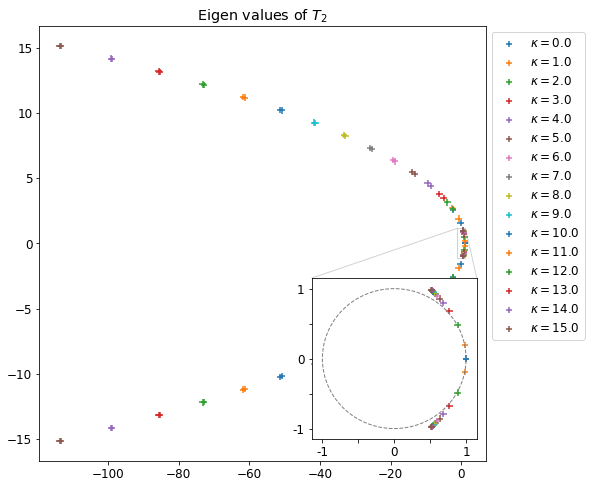
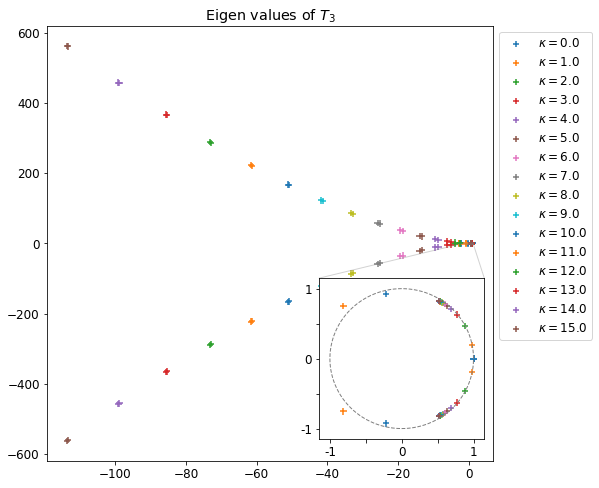
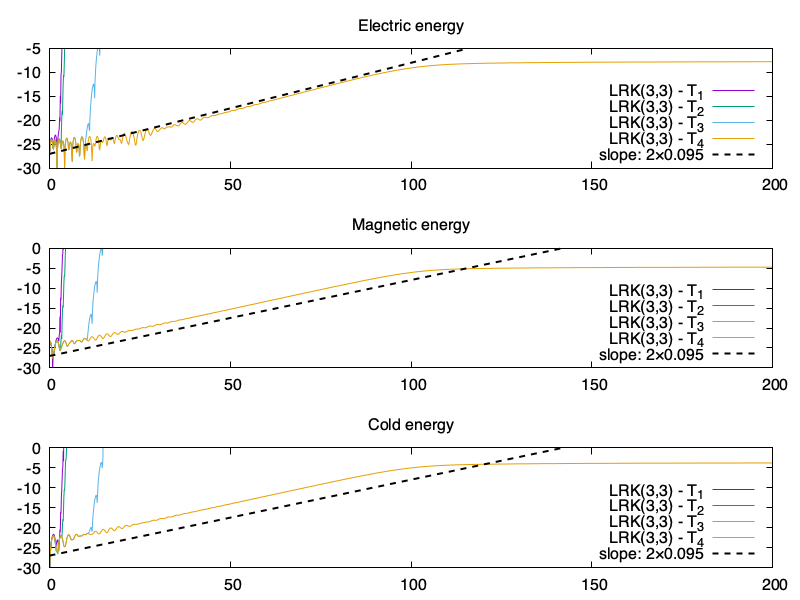
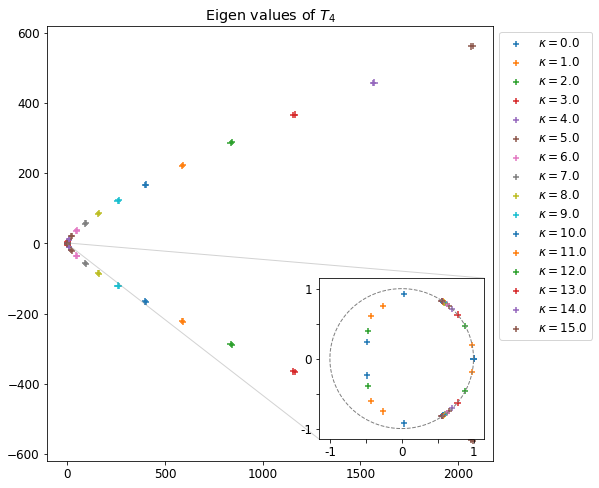
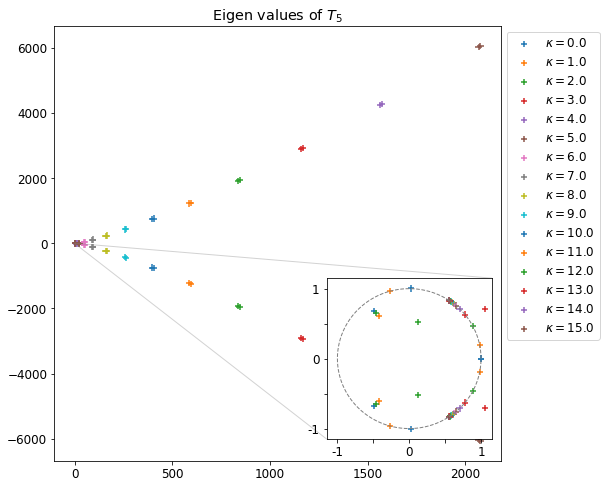
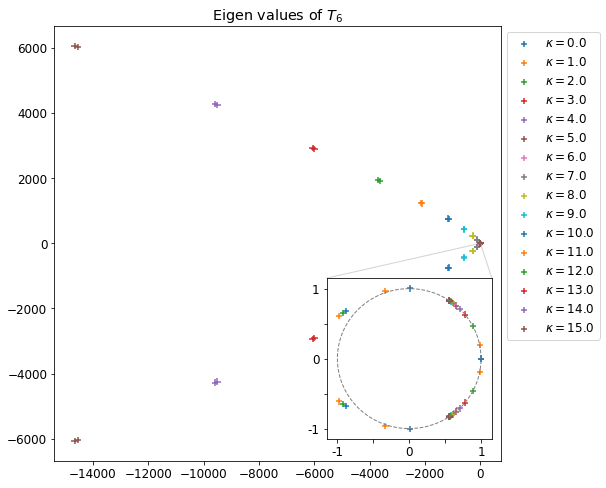
![les 11 points de Leja sur l’intervalle [-100,100].](img/leja_211109.png)
![Partie réelle de L_{10}(iy) pour y\in[-100,100]](img/leja_L10_re_211109.png)
![Partie imaginaire de L_{10}(iy) pour y\in[-100,100]](img/leja_L10_im_211109.png)
![Module de L_{10}(iy) pour y\in[-100,100]](img/leja_L10_module_211109.png)
![Points sur le plan complexe L_{10}(iy) pour y\in[-100,100]](img/leja_L10_211109.png)
![Partie réelle de L_{5}(iy) pour y\in[-100,100]](img/leja_L5_re_211109.png)
![Partie imaginaire de L_{5}(iy) pour y\in[-100,100]](img/leja_L5_im_211109.png)
![Module de L_{5}(iy) pour y\in[-100,100]](img/leja_L5_module_211109.png)
![Points sur le plan complexe L_{5}(iy) pour y\in[-100,100]](img/leja_L5_211109.png)